
[Big Data]빅데이터 기술 소개
데이터팀의 역할: 데이터 팀은 어떤 역할을 수행하는가?
데이터 팀의 미션
- 신뢰할 수 있고 빠르게 이용가능한 데이터를 바탕으로 부가가치 생성
데이터 팀의 목표1
- 고품질의 데이터를 제공하여 정책 결정에 사용
- 결정과학(Decision Science)라고 부르기도 함. 그리고 이 일을 하는 사람을 데이터 애널리스트라고 부르기도 함.
- 데이터 참고 결정(data informed decisions)을 가능하게 함: 내가 가고싶은 방향이 있고, 이를 위해 데이터를 참고
- vs. 데이터 기반 결정(data driven decisions): 내가 가고싶은 방향은 없고, 데이터가 말하는 대로 간다.
- 데이터는 기본적으로 과거의 현상을 보여주기만 하기 때문에, 전자인 데이터 참고 결정이 더 좋다.
데이터 팀의 목표2
- 고품질 데이터를 필요할 때 제공하여 사용자의 서비스 경험 개선
- 추천, 검색 등을 사용자의 과거 기록을 보고 개인화를 한다 -> 데이터 과학자들이 하는 일.
- 머신 러닝과 같은 데이터 기반 알고리즘을 통해 개선
- 예) 개인화를 바탕으로 한 추천(Recommendation)과 검색 기능 제공
- 하지만 사람의 개입/모움이 반드시 필요(human-in-the-loop)
데이터 인프라
- 데이터 엔지니어는 데이터 웨어하우스를 만들고, 회사에서 필요한 내/외부 데이터를 적제한다. 데이터 엔지니어가 데이터 파이프라인을 구현한다.(ETL, 추출 변환 적재)
- 데이터 분석가들이 데이터 웨어하우스에 있는 데이터를 기반으로 다양한 회사 지표들을 만든다.(매출액, 수요…)
- 데이터 과학자가 개인화를 머신러닝/인공지능으로 만든다.
데이터 팀의 발전 : 1. 데이터 인프라 구축
- 데이터 인프라: 데이터 웨어하우스와 ETL(Extract, Transform, Load)
- 데이터 웨어하우스: 회사에 필요한 모든 데이터들을 저장하는 중앙 데이터베이스
- ETL: 소스에 존재하는 데이터들을 데이터 웨어하우스로 복사해오는 코드를 지칭. 보통 파이썬으로 작성
- 데이터 인프라의 구축은 데이터 엔지니어가 수행함
데이터 웨어하우스란?
- 회사에 필요한 모든 데이터를 모아놓은 중앙 데이터베이스(SQL), 웹서비스의 데이터베이스와는 완전 다른것!!
- 데이터의 크기에 맞게 어떤 데이터베이스를 사용할지 선택
- 크기가 커진다면 AWS의 Redshift, 구글 클라우드의 BigQuery, 스노우플레이크(Snowflake)나 오픈소스 기반의 하둡/스팍을 사용하는 것을 추천: 이 모두 SQL을 지원
- 중요 포인트는 프로덕션용 데이터베이스와 별개의 데이터베이스라는 점
- 데이터 웨어하우스 구축은 진정한 데이터 조직이 되는 첫번째 스텝
ETL이란?
- 다른 곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
- Extract: 외부 데이터 소스에서 데이터를 추출
- Transform: 데이터의 포맷을 원하는 형태로 변환
- Load: 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재(보통 테이블 형태로 적재된다.)
- 이는 코딩을 필요로 하며 가장 많이 쓰이는 프레임웤은 Airflow
- Airflow는 오픈소스 프로젝트로 파이썬3 기반
- 에어비엔비, 우버, 리프트, 쿠팡 등에서 사용
- AWS와 구글클라우드에서도 지원
- 흔한 데이터 소스의 경우 SaaS(Software as a Service) 사용 가능
- Five Tran, Stitch Data, …
- Five Tran, Stitch Data, …
- Airflow는 오픈소스 프로젝트로 파이썬3 기반
데이터 팀의 발전: 2. 데이터 분석 수행
- 데이터 분석이란?
- 회사와 팀별 중요 지표(metircs) 정의하고 대시보드 형태로 시각화(visualization)
- 이외에도 데이터와 관련한 다양한 분석/리포팅 임무 수행
- 중요 지표의 예: 매출액, 월간/주간 액티브 사용자수, …
- 이는 데이터 분석가(Data Analyst)가 맡는 일임
시각화 대시보드란?
- 보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
- 지표의 경우 3A(Accessible, Actionable, Auditable)가 중요
- 가장 널리 사용되는 대시보드:
- 구글 클라우드의 룩커(Looker)
- 세일즈포스의 태블로(Tableau)
- 마이크로소프트의 파워 BI(Power BI)
- 오픈소스 아파치 수퍼셋(Superset)
데이터 팀의 발전: 3.머신러닝/인공지능 적용
- 데이터 과학 적용: 사용자 경험 개선(추천, 검색 등의 개인화)
- 데이터 인프라에 저장된 데이터를 기반(훈련용 데이터)으로 지도기계학습(supervised machine learning)을 통해 머신러닝 모델들을 개발하여 추천, 검색들을 개인화하는 것이 일반적인 패턴
데이터 팀의 구성원: 데이터 팀을 구성하는 사람들은 누구인가?
데이터 팀에는 누가 있는가?
- 데이터 엔지니어(Data Engineer)
- 데이터 인프라(데이터 웨어하우스와 ETL) 구축
- 데이터 엔지니어가 없으면 회사 들어가서 땅 위에서 헤엄치는 격이 될 수 있다. 데이터 엔지니어가 있어야 데이터 분석가, 과학자들이 일을 할 수 있다.
- 데이터 분석가(Data Analyst)
- 데이터 웨어하우스의 데이터를 기반으로 지표를 만들고 시각화(대시보드)
- 내부 직원들의 데이터 관련 질문 응답
- 데이터 과학자(Data Scientist)
- 우리가 지금 공부하는 과정!
- 과거 데이터를 기반으로 미래를 예측하는 머신러닝 모델을 만들어 고객들의 서비스 경험을 개선(개인화 혹은 자동화 혹은 최적화)
- 작은 회사에서는 한 사람이 몇개의 역할을 동시에 수행하기도 함
데이터 엔지니어의 역할
- 기본적으로는 소프트웨어 엔지니어
- 파이썬이 대세. 자바 혹은 스칼라와 같은 언어도 아는 것이 좋음
- 데이터 웨어하우스 구축
- 데이터 웨어하우스를 만들고 이를 관리. 클라우드로 가는 것이 추세
- AWS의 Redshift, 구글클라우드의 BigQuery, 스노우플레이크
- 관련해서 중요한 작업중의 하나는 ETL 코드를 작성하고 주기적으로 실행해주는 것
- ETL 스케줄러 혹은 프레임웤이 필요(Airflow라는 오픈소스가 대세)
- 데이터 웨어하우스를 만들고 이를 관리. 클라우드로 가는 것이 추세
- 데이터 분석가와 과학자 지원
- 데이터 분석가, 데이터 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해주는 것이 데이터 엔지니어의 중요한 역할 중 하나
- 데이터 분석가, 데이터 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해주는 것이 데이터 엔지니어의 중요한 역할 중 하나
데이터 분석가의 역할
- 비즈니스 인텔리전스를 책임짐
- 중요 지표를 정의하고 이를 대시보드 형태로 시각화
- 대시보드로는 태블로(Tableau)와 룩커(Looker)등의 툴이 가장 흔히 사용됨
- 오픈소스로는 수퍼셋(Superset)이 많이 사용됨
- 이런 일을 수행하려면 비즈니스 도메인에 대한 깊은 지식 필요
- 중요 지표를 정의하고 이를 대시보드 형태로 시각화
- 회사내 다른 팀들의 데이터 관련 질문 대답
- 임원들이나 팀 리드들이 데이터 기반 결정을 내릴 수 있도록 도와줌
- 질문들이 굉장히 많고 반복적이기에 어떻게 셀프서비스로 만들 수 있느냐가 관건
- 필요한 스킬셋
- SQL, 통계적 지식
- 비즈니스 도메인에 관한 깊은 지식
- 보통 코딩을 하지는 않음
- 이 직군은 수요보다 공급이 큰 상황이다. 코딩을 할 줄 알면 경쟁력을 키울 수 있다!
데이터 분석가의 딜레마
- 보통 많은 수의 긴급한 데이터 관련 질문들에 시달림
- 많은 경우 현업팀에 소속되기도 함
- 내 커리어에서 다음은 무엇인가?
- 소속감이 불분명하고 내 고과 기준이 불명확해짐
- 데이터 분석가의 경우 조직구조가 더 중요함
데이터 과학자의 역할
- 머신러닝 형태로 사용자들의 경험을 개선
- 문제에 맞춰 가설을 세우고 데이터를 수집한 후에 예측 모델을 만들고 이를 테스트
- 장시간이 필요하지만 이를 짧은 사이클로 단순하게 시작해서 고도화하는 것이 좋음
- 테스트는 가능하면 A/B 테스트를 수행하는 것이 더 좋음
- 문제에 맞춰 가설을 세우고 데이터를 수집한 후에 예측 모델을 만들고 이를 테스트
- 데이터 과학자에게 필요한 스킬셋
- 머신러닝/인공지능에 대한 깊은 지식과 경험
- 코딩 능력(파이썬과 SQL)
- 통계 지식, 수학 지식(통계 지식이 더 중요!!)
- 끈기와 열정. 박사 학위가 도움이 되는 이유 중의 하나.
훌륭한 데이터 과학자란?
- 열정과 끈기
- 다양한 경험
- 코딩 능력
- 현실적인 접근 방법
- 애자일 기반의 모델링
- 딥러닝이 모든 문제의 해답은 아님을 명심
- 과학적인 접근 방법
- 지표기반 접근
- 내가 만드는 모델의 목표는 무엇이고 그걸 어떻게 측정할 것인가?
- 제일 중요한 것은 모델링을 위한 데이터의 존재 여부!
머신러닝 모델링 사이클
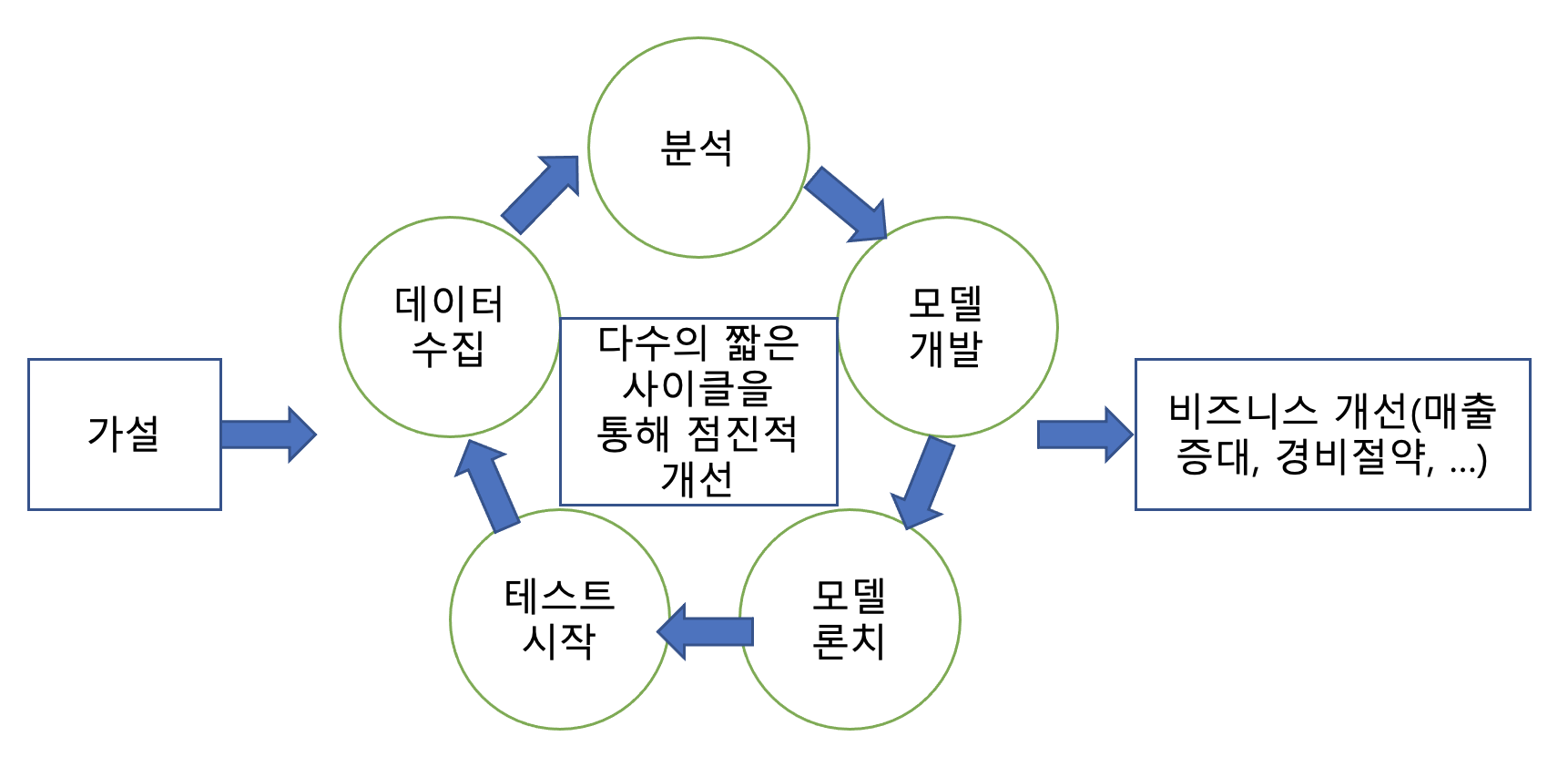
모델 론치할때 보통 A/B 테스트를 통해 이뤄짐.
폭포수 개발방법론 vs. 애자일 개발방법론
- 빠르게 변화하는 트랜드에 발맞추기 위해 폭포수보다는 애자일 개발방법론이 쓰인다.
A/B 테스트란?
- 온라인 서비스에서 새 기능의 임팩트를 객관적으로 측정하는 방법
- 의료쪽에서 무작위 대조 시험(Randomized Controlled Trial)을 온라인으로 옮긴 것.
- 일반적인 웹서비스에서 실제 사용자를 대상으로 하는 테스트이다.
- 새로운 기능을 론치함으로 생기는 위험부담을 줄이는 방법
- 100%의 사용자에게 론치하는 것이 아니라 작게 시작하고 관찰 후 결정
- 실제 예제: 추천을 기계학습기반으로 바꾼 경우
- 먼저 5%의 사용자에게만 론치하고 나머지 95%의 사용자와 매출액과 같은 중요 지표를 가지고 비교
- 5% 대상으로 별문제 없으면 10%, 20% 이런 식으로 점진적으로 키우고 최종적으로 100%로 론치
- 보통 사용자들을 2개의 그룹으로 나누고 시간을 두고 관련 지표를 비교
- 한 그룹은 기존 기능에 그대로 노출(control)
- 다른 그룹은 새로운 기능에 노출(test)
- 두 그룹의 특성이 비슷하도록 (성별, 나이 등등) 랜덤하게 섞어서 배분
- 가설과 영향받는 지표를 미리 정하고 시작하는 것이 일반적
- 지표의 경우 성공/실패 기준까지 생각해보는 것이 필요
- 지표의 경우 성공/실패 기준까지 생각해보는 것이 필요
데이터 팀의 조직구조: 현업에서 데이터 팀은 어떻게 다른 팀들과 협업하는가?
중앙집중 구조: 모든 데이터 팀원들이 하나의 팀으로 존재
- 데이터 팀 관점에서는 가장 좋은 구조. 안에서 같이 발전하며 커리어 패스를 정하기 좋으나 다른 부서들이 싫어함.
- 일의 우선 순위는 중앙 데이터팀이 최종 결정
- 데이터 팀원들간의 지식과 경험의 공유가 쉬워지고 커리어 경로가 더 잘 보임
- 하지만 현업부서들의 만족도는 상대적으로 떨어짐
분산 구조: 데이터 팀이 현업 부서별로 존재
- 일의 우선 순위는 각 팀별로 결정
- 데이터 일을 하는 사람들간의 지식/경험의 공유가 힘들고 데이터 인프라나 데이터의 공유가 힘들어짐
- 현업부서들의 만족도는 처음에는 좋지만 많은 수의 데이터 팀원들이 회사를 그만두게 됨
- 많은 회사들이 중앙과 분산 구조를 왔다갔다함.
중앙집중과 분산의 하이브리드 모델
- 가장 이상적인 조직 구조
- 데이터 팀원들은 일부는 중앙에서 인프라적인 일을 수행하고 일부는 현업팀으로 파견식으로 일하되 주기적으로 일을 변경
- 데이터팀 안에서 커리어 경로가 만들어짐
모델 개발시 고려할 점: 현업에서 모델 개발시 알아야할 점들은?
- 데이터 과학자가 현업에서 일할 때 발생할 수 있는 문제점들!
모델 개발시 데이터 과학자들의 일반적인 생각
- 데이터 과학자: 아주 좋은 머신러닝 모델을 만들고 말겠어!
- 엔지니어: 모델 만들고 나서 다음 스텝은 뭐야?
- 데이터 과학자: ???
- 즉 운영상에 있어서의 어떤 문제가 있을지 생각을 덜 하게 된다. 좋은 데이터 과학자는 모델을 어떻게 만들어야 엔지니어가 production에서 론치하고 운영하는 데 쉬울지 신경쓴다.
마찰이 생기는 지점 - 개발된 모델의 이양 관련
- 많은 수의 데이터 과학자들은 R을 비롯한 다양한 툴로 모델 개발
- 하지만 실제 프로덕션 환경은 다양한 모델들을 지원하지 못함
- 개발/검증된 모델의 프로덕션 환경 론치시 시간이 걸리고 오류 가능성이 존재
- 심한 경우 모델 관련 개발을 다시 해야함(피쳐 계산과 모델 실앻 관련)
모델 개발시 꼭 기억할 포인트
- 누군가 모델 개발부터 최종 론치까지 책임질 사람이 필요
- 모델 개발은 시작일 뿐이고 성공적인 프로덕션 론치가 최종적인 목표
- 이 일에 참여하는 사람들이 같이 크레딧을 받아야 협업이 더 쉬워짐
- 최종 론치하는 엔지니어들과 소통하는 것이 중요
- 모델 개발 초기부터 개발/론치 과정을 구체화하고 소통
- 모델 개발시 모델을 어떻게 검증할 것인지?
- 모델을 어떤 형태로 엔지니어들에게 넘길 것인지?
- 피쳐 계산을 어떻게 하는지? 모델 자체는 어떤 포맷인지?
- 모델을 프로덕션에서 A/B 테스트할 것인지?
- 한다면 최종 성공판단 지표가 무엇인지?
- 개발된 모델이 바로 프로덕션에 론치가능한 프로세스/프레임웍이 필요
- 예를 들어 R로 개발된 모델은 바로 프로덕션 론치가 불가능
- 트위터: 데이터 과학자들에게 특정 파이썬 라이브러리로 모델개발 정책화
- 툴을 하나로 통일하면 제반 개발과 론치 관련 프레임웍의 개발이 쉬워짐
- AWS의 SageMaker: 머신러닝 모델개발, 검증, 론치 프레임웍
- 검증된 모델을 버튼 클릭 하나로 API 형태로 론치 가능!
- Google Cloud와 Azure도 비슷한 프레임웍 지원
- 첫 모델 론치는 시작일 뿐
- 론치가 아닌 운영을 위해 점진적인 개선을 이뤄내는 것이 중요!
- 데이터 과학자의 경우 모델 개발하고 끝이 아니라는 점 명심!
- 결국 피드백 루프가 필요
- 운영에서 생기는 데이터를 가지고 개선점 찾기
- 검색이라면 CTR(Click Through Rate)을 모니터링하고 모든 데이터를 기록
- 주기적으로 모델을 재빌딩
- 온라인 러닝: 모델이 프로덕션에서 사용되면서 계속적으로 업데이트되는 방식의 머신러닝
- 운영에서 생기는 데이터를 가지고 개선점 찾기
데이터를 통해 매출이 생겨야 한다
- 어느 조직이건 회사에서의 존재 이유는 매출 창조 혹은 경비 절감
- 데이터 인프라와 데이터 팀원(데이터 과학자)의 몸값은 상대적으로 높음
- 직접적이건 간접적이건 데이터를 통해 회사 수익에 긍정적인 영향을 끼쳐야함
- 데이터 조직의 수장의 역할이 아주 중요
- 위와 옆으로 잘 매니지를 해야함
- 다시 한번 데이터 인프라의 구성이 첫 번째라는 점을 명심하되 단기적으로 좋은 결과를 낼 방법을 찾아야함
데이터 인프라가 첫 번째 스텝!
- 데이터 인프라 없이는 데이터 분석이나 모델링은 불가능
- 하지만 아주 작은 회사에서 생존이 더 중요한 문제라 데이터 인프라는 조금더 성장한 뒤에 걱정해도 됨
- 첫 번째 팀원은 인프라 구축 이외에도 약간의 분석/모델링 스킬이 있는 사람이 최적
- 고려점
- 클라우드 vs. 직접 구성
- 배치 vs. 실시간
데이터의 품질이 아주 중요
- Garbage In Garbage Out
- 데이터 과학자가 가장 많은 시간을 쏟는 분야는?
- 데이터 청소 작업!
- 모델링에 드는 시간을 100이라고 하면 그중 70은 데이터 클린업에 들어감
- 중요 데이터의 경우 좀더 품질 유지에 노력이 필요
- 어디에 데이터가 있는지?
- 이 데이터의 품질에 혹시 문제가 있는지 계속적으로 모니터링
항상 지표부터 생각
- 무슨 일을 하건 그 일의 성공 척도(지표)를 처음부터 생각
- 또한 나름대로 가설을 세우는 것이 인사이트를 키우는데 큰 도움이 됨
- 지표의 계산에 있어서 객관성이 중요
- 계산된 지표를 아무도 못 믿는다면 큰 문제
- 지표를 어떻게 계산할 것인지 그리고 이걸 다른 사람들에게 어떻게 설명할지 고려
가능하면 간단한 솔루션으로 시작
- 모든 문제를 딥러닝으로 해결해야 하나?
- IF문 몇개의 간단한 논리로 해결할 수 있는지 부터 고민!
- 실제 회사에서 딥러닝으로 문제를 해결하는 경우는 드뭄. 왜 동작하는지 설명도 힘들고 개발과 론치 모두 시간이 걸림
- 반복 기반의 점진적인 개발방식 vs. 한 큐에 모델 만들기
- 후자는 시간만 오래 걸리고 최종 성과는 안 좋을 확률이 높음
- 전자로 가면서 원하는 결과가 나오면 그 때 중단. 더 개선할 필요 없음
요약
- 데이터팀의 목표는 신뢰할 수 있는 데이터를 바탕으로 부가가치 생성
- 데이터 직군에는 엔지니어, 분석가, 과학자 이렇게 세 종류가 존재
- 데이터 팀 조직 구조에는 중앙집중, 분산, 하이브리드의 세 종류가 존재
- 모델 개발은 론치와 운영에 초점을 맞춰야 함
- 데이터 팀의 존재 여부는 여타 팀과 마찬가지로 수익증대라는 점 명심
- 단순한 솔루션이 제일 좋은 솔루션(모든 문제에 딥러닝을 쓰지는 말자)