
[Machine Learning 기초]기계학습과 수학 리뷰
기계 학습과 수학
기계 학습에서 수학의 역할
- 수학은 목적함수를 정의하고, 목적함수의 최저점을 찾아주는 최적화 이론 제공
- 최적화 이론에 학습률, 멈춤조건과 같은 제어를 추가하여 알고리즘 구축
- 사람은 알고리즘을 설계하고 데이터를 수집
- 기계학습은 수학/알고리즘/사람이 수집하는데이터 로 이루어진다.
선형대수
벡터와 행렬
- 벡터
- 샘플을 특징 벡터(feature vector)로 표현
- 요소의 종류와 크기 표현
- 예) $x\in R^n$
- 데이터 집합의 여러 개 특징 벡터를 첨자로 구분$(x_i)$
- 예) $x_1 = \begin{pmatrix} 1&\cr 2&\cr 3 \end{pmatrix}$
- 행렬
- 여러개의 벡터를 담음
- 요소: $x_{ij}$, i번째 행과 j번째 열로 이루어짐
- 훈련집합을 담은 행렬을 설계행렬(design matrix)이라 부름
- 행렬 A의 전치행렬(transpose matrix) $A^T$
- 열이 행이 됨
- 표현을 쉽게 하기 위해 많이 씀
- $A^T_{ij} = A_{ij}$
- $(AB)^T = B^TA^T$
- 행렬을 이용하면 방정식을 간결하게 표현가능
- 특수 행렬들
- 정사각행렬(정방행렬, square matirx) : 행개수==열개수
- 대각행렬(diagonal matrix) : 대각요소 제외하고 모두 0
- 단위행렬(identity matrix) : 대각요소값이 모두 1이고 나머지 0
- 대칭행렬(symmetric metrix) : 대각요소 기준으로 서로 대칭인 값을 가짐
- 행렬 연산
- 행렬 곱셈(matirx product, dot product) : C = AB
- 행렬의 곱셈은 행렬의 내적이다.
- A의 열 수 = B의 행 수 이어야 곱셈이 가능하다!
- 교환법칙 성립하지 않음 : AB != BA
- 분배법칙과 결합법칙 성립 : A(B+C) = AB+AC, A(BC) = (AB)C
- 행렬 곱셈(matirx product, dot product) : C = AB
- 벡터의 내적(inner product) : $a * b = a^T * b$
- 텐서(tensor)
- 3차원 이상의 구조를 가진 배열
- 0차 = 수(scalar)
- 1차 = 벡터
- 2차 = 행렬
- 고차원(예 : 3차원 구조의 RGB 컬러 영상)
- 3차원 이상의 구조를 가진 배열
놈과 유사도
- 유사도(similarity)와 거리(distance)
- 코사인 유사도 : $cosine similarity(a,b) = {a \above 1pt \left | a \right |}\cdot {b \above 1pt \left | b \right |}=cos(\theta)$
- 코사인 유사도 : $cosine similarity(a,b) = {a \above 1pt \left | a \right |}\cdot {b \above 1pt \left | b \right |}=cos(\theta)$
- 벡터와 행렬의 거리(크기)를 놈(norm)으로 측정
- 벡터의 p차 놈
- p차 놈 :
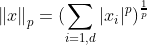
-
최대 놈 : $\left | x \right |_\infty = max( x_1 , x_2 , …, x_d )$
- p차 놈 :
- 행렬의 프로베니우스 놈(Frobenius norm) : 행렬의 크기를 측정
- 프로베니우스 놈 :
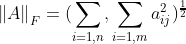
- 프로베니우스 놈 :
- 벡터의 p차 놈
- 놈을 사용하는 경우
- 벡터의 거리(크기)의 경우
- 하강 기울기(gradient descent)의 규제 경우(규제를 통해 범위 제한, 오버피팅 방지!)
퍼셉트론의 해석
- 퍼셉트론(perceptron)
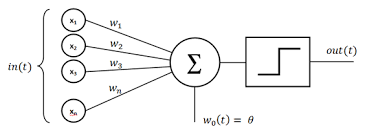
- 1958년 고안한 분류기(classification)모델
- 주어진 데이터 값을 기준을 붙여서 필터링 하는 것
- 퍼셉트론의 동작을 수식으로 표현하면
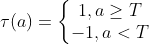
- 활성함수(activation function) 타우 로는 계단함수 사용
- 학습의 정의
- 추론 : 학습을 마친 알고리즘을 현장의 새로운 데이터에 적용하는 작업
- 분류라는 과업 : $o = \tau(Wx)$
- $o$=?, $W, x$=앎
- 훈련 : 훈련집합의 샘플에 대해 다음 식을 가장 잘 만족하는 W를 찾아내는 작업
- 학습이라는 과업 : $o = \tau(Wx)$
- $W$=?, $o,x$=앎
- 추론 : 학습을 마친 알고리즘을 현장의 새로운 데이터에 적용하는 작업
- 현대 기계 학습에서 심층학습은 퍼셉트론을 여러 층으로 확장하여 만듦
선형결합과 벡터공간
- 벡터
- 공간상의 한 점으로 화살표 끝이 벡터의 좌표에 해당
- 선형결합이 만드는 벡터공간
- 기저벡터 a와 b의 선형결합
- $c = \alpha_1a + \alpha_2b$
- 선형결합으로 만들어지는 공간을 벡터공간이라 부름
- 기저벡터 a와 b의 선형결합
역행렬
- 정사각행렬 $A$의 역행렬 $A^{-1}$
- $A^{-1}A = AA^{-1} = I$
- 역행렬을 활용한 방정식 표현과 해
- 방정식 $Ax = b$의 확장
- $A\in R^{m\times n}$ : 알고 있는 행렬
- $b\in R^{n}$ : 알고 있는 벡터
- $x\in R^{m}$ : 알고 싶은 모르는 벡터
- $A_1,:x = A_{1,1}x_1+A_{1,2}x_2+…+A_{1,n}x_n = b_1$
- $A_m,:x = A_{m,1}x_1+A_{m,2}x_2+…+A_{m,n}x_n = b_m$
- 선형 방정식의 경우
- 불능 : 해 없음
- 부정 : 다수의 해 존재
- 유일해 존재 : 역행렬을 이용하여 해를 구함
- $AX = b$
- $A^{-1}x = A^{-1}b$
- $I_nx = A^{-1}b$
- $x = A^{-1}b$
- 방정식 $Ax = b$의 확장
- 정리 : 다음 성질은 서로 필요충분조건이다.
- $A$는 역행렬을 가진다. 즉, 특이행렬이 아니다.
- $A$는 최대계수를 가진다.
- $A$의 모든 행이 선형독립이다.
- $A$의 모든 열이 선형독립이다.
- $A$의 행렬식은 0이 아니다.
- $A^TA$는 양의 정부호(positive definite) 대칭 행렬이다.
- $A$의 고윳값은 모두 0이 아니다.
- 행렬 A의 행렬식 $det(A)$
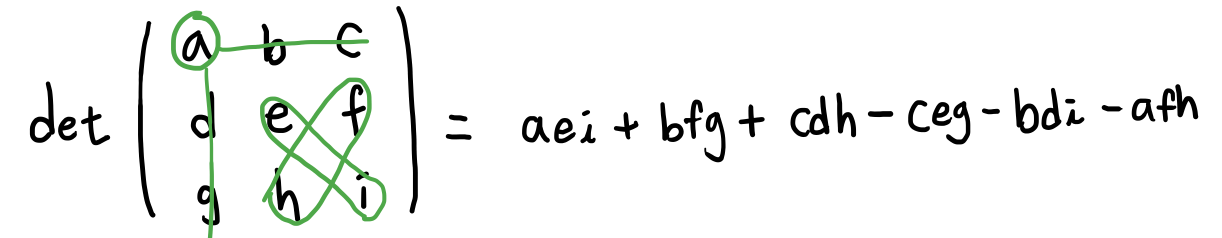
- 역행렬의 존재 유무
- $det(A)=0$ : 역행렬 없음
- $det(A)\neq0$ : 역행렬 존재
- 기하학적 의미 : 행렬식은 주어진 행렬의 곱에 의한 공간의 확장 또는 축소 해석
- 만약 $det(A)=0$ -> 하나의 차원을 따라 축소되어 부피를 잃음
- 만약 $det(A)=1$ -> 부피 유지한 변환/방향 보존 됨
- 만약 $det(A)=-1$ -> 부피 유지한 변환/방향 보존 안됨(마이너스)
- 만약 $det(A)=5$ -> 5배 부피 확장되며 방향 보존
- 역행렬의 존재 유무
- 정부호행렬
- 행렬의 공간이 어떻게 생겼는지 알기 위해 쓴다.
- 양의 정부호 행렬 : 0이 아닌 모든 벡터 $x$에 대해, $x^TAx > 0$
- 성질
- 고유값 모두 양수
- 역행렬도 정부호 행렬
- $det(A)\neq0$ 역행렬 존재
- 정부호 행렬의 종류
- 양의 준정부호 행렬 : 0이 아닌 모든 벡터 $x$에 대해, $x^TAx \geq 0$
- 음의 정부호 행렬 : 0이 아닌 모든 벡터 $x$에 대해, $x^TAx < 0$
- 음의 준정부호 행렬 : 0이 아닌 모든 벡터 $x$에 대해, $x^TAx \leq 0$
행렬분해
- 분해란?
- 정수를 소인수분해 하듯이, 행렬도 분해하면 여러모로 유용함
- 고윳값(eigenvalue)과 고유 벡터(eigenvector)
- $Av = \lambda v$ : 고유 벡터 $v$와 고윳값 $\lambda$
- A에 대해 공간변환이 될 때, 고유벡터에 따라 크기가 변함.
- 고윳값과 고유벡터의 효과
- A라는 행렬에 의해 공간이 변할 때, 고유벡터(v1,v2)는 축이되어 크기를 변환시킨다.
- 고윳값과 고유벡터로 PCA를 할 수 있다.
- 고유분해
- $A = Q\Lambda Q^{-1}$
- $Q$는 $\Lambda$의 고유 벡터를 열에 배치한 행렬이고 $\Lambda$는 고윳값을 대각선에 배치한 대각행렬
- 고유분해는 고유값과 해당 고유 벡터가 존재하는 정사각행렬에만 적용 가능
- 하지만, 기계학습에서는 정사각행렬이 아닌 경우의 분해도 필요하므로 고유분해는 한계
- $A = Q\Lambda Q^{-1}$
- 특잇값 분해
- $A = U\Sigma V^T$
- 특이행렬 $U$ : $AA^T$의 고유 벡터를 열에 배치한 n*n 행렬
- 특이행렬 $V$ : $A^TA$의 고유 벡터를 열에 배치한 m*m 행렬
- $\Sigma:AA^T$의 고윳값의 제곱근을 대각선에 배치한 n*m 대각행렬
- $A = U\Sigma V^T$
- 특잇값 분해의 기하학적 해석
- $V$ : 회전 변환
- $D$ : 크기 변환
- $U$ : 회전 변환
- 특잇값 분해는 정사각행렬이 아닌 행렬의 역행렬 계산에 사용됨
확률과 통계
- 기계 학습이 처리할 데이터는 불확실한 세상(잡음이 들어감)에서 발생하므로, 불확실성을 다루는 확률과 통계를 잘 활용해야 함.
- target distribution으로부터 나오는 샘플을 통해 타겟이 어떻게 생겼는지 설명하기 위해 쓰는 것이 모델이다.
확률 기초
- 확률변수
- 확률분포
- 크게 두가지가 있다.
- 확률질량함수 : 이산확률변수 ($P(x=1) = {1 \above 1pt 2}$)
- 확률밀도함수 : 연속확률변수
- 확률벡터
- 확률변수를 요소로 가짐. 벡터 하나하나의 요소값이 확률변수이다.
- 곱(AND)규칙과 합(OR)규칙
- 조건부 확률에 의한 결합확률 계산
- 곱 규칙 :
-
$P(y,x) = P(x y)P(y)$ - 독립인 경우 $P(x)P(y)$
-
- 합 규칙과 곱 규칙에 의한 주변확률 계산
- 합 규칙 :
-
$P(x) = \sum_{y}P(y,x) = \sum_{y}P(x y)P(y)$
-
- 합 규칙 :
- 곱 규칙 :
- 조건부 확률에 의한 결합확률 계산
- 조건부 확률
- 확률의 연쇄 법칙(chain rule)
- 독립
- 조건부 독립
- 기대값
joint probability(결합확률)과 조건부확률이 서로 변환 가능함이 중요!
베이즈 정리와 기계 학습
- 베이즈 정리
$P(y,x) = P(x|y)P(y) = P(x,y) = P(y|x)P(x)$
$P(y|x) = {P(x|y)P(y) \above 1pt P(x)}$ - 다음 질문을 위의 식으로 쓸 수 있음
- “하얀 공이 나왔다는 사실만 알고 어느 병에서 나왔는지 모르는데, 어느 병인지 추정하라.” x=하얀공, y=병
- “하얀 공이 나왔다는 사실만 알고 어느 병에서 나왔는지 모르는데, 어느 병인지 추정하라.” x=하얀공, y=병
- 베이즈 정리의 해석
- 사후확률 = 우도확률*사전확률
-
P(y x) : 사후확률 -
P(x y) : 우도 - P(y) : 사전확률
기계학습에서는 대부분 사후확률을 풀고 싶어한다.
확률은 어떤 분포에서부터 우리가 가지고있는 모든 숫자들을 정량화시켜놓고 그 분포로부터 데이터를 생성해서 유추하는 것이다.
확률은 정확한 값이고 우도는 덜 정확한 값이라고 할 수 있다.
확률은 전체적인 것에 대한 정확한 값이다.
우도는 관찰된 값에서만 확인할 수 있다.
실제 상황에서 우도는 쉽게 구할 수 있지만, 확률분포는 쉽게 구할 수 없다.
-
- 사후확률 = 우도확률*사전확률
- 기계 학습에 적용
- 특징벡터 $x$, 분류 $y$
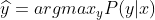 -> 분류 문제를 argmax로 표현한 식
-> 분류 문제를 argmax로 표현한 식
-
**사후확률 $P(y x)$를 직접 추정하는 일은 아주 단순한 경우를 빼고 **불가능 - 따라서 베이즈 정리를 이용하여 추정함
- 사전확률은 다음 식으로 추정. 사전확률 : $P(y = c_i) = {n_i \above 1pt n}$
- 우도확률은 밀도추정 기법으로 추정
정리하자면, 기계학습에서 사후확률로 문제를 풀고 싶어하는게 목적인데, 사후확률을 직접적으로 푸는 것이 불가능하니 사전확률과 우도를 통해서 푸는 것이다.
- 특징벡터 $x$, 분류 $y$
최대 우도
- 매개변수(모수, 파라미터) $\Theta$를 모르는 상황(즉 확률분포를 모르는 상황에서)에서 매개변수를 추정하는 문제
- 데이터 X가 주어졌을 때, X를 발생시켰을 가능성을 최대로 하는 매개변수 $\Theta$의 값을 찾아라.
- 최대 우도 : 어떤 확률변수의 관찰된 값들을 토대로 그 확률변수의 매개변수를 구하는 방법
- 일반화하면,
- 최대우도추정
-
$\Theta = argmax_\Theta P(X \Theta)$
-
- 최대우도추정
- 수치 문제를 피하기 위해 로그 표현으로 바꾸면,
- 최대우도추정
-
$\Theta = argmax_\Theta P(X \Theta)= argmax_\Theta \sum_{i=1}^{n} log P(x_i \Theta)$
-
- 단조 증가하는 로그 함수를 이용하여 계산 단순화
- X가 joint probability로 이루어져 곱셈을 해야하는데 이는 어려우므로 단순하게 해당 값 자체를 최대로 만들어주는 세타값을 찾도록 로그 표현으로 바꾸는 것이다.
- 최대우도추정
- 일반화하면,
평균과 분산
- 데이터의 요약 정보로서 평균과 분산
- 평균 벡터(치우침 정도)와 공분산 행렬(확률변수의 상관정도)
유용한 확률분포
- 가우시안 분포
- 평균 $\mu$와 분산 $\sigma^2$으로 정의
- 다차원 가우시안 분포 ; 평균벡터 $\mu$와 공분산행렬 $\Sigma$로 정의
- 베르누이분포
- 성공(x=1)확률 이 p이고 실패(x=0) 확률이 1-p인 분포
- 한번 시행했을 때
- 이항분포
- 성공확률이 p인 베르누이 실험을 m번 수행할 때 성공할 횟수의 확률분포
- 베르누이 분포를 m번 수행했을 때로 확장
- 확률질량함수
- 확률 분포와 연관된 유용한 함수들
- 로지스틱 시그모이드 함수
- 비선형 함수.
- 활성함수로써 신경망에서 쓰임. 주어져 있는 x를 y로 치환할 때 0~1사이 값으로 만들어줌. 베르누이 분포로부터 로지스틱 시그모이드가 얻어짐.
- 일반적으로 베르누이 분포의 매개변수를 조정을 통해 얻어짐
- 소프트플러스함수
- 비선형 함수
- 활성함수로써 신경망에서 쓰임. 정규분포의 값들을 조정해서 얻어짐.
- 정규 분포의 매개변수의 조정을 통해 얻어짐
- 로지스틱 시그모이드 함수
- 지수 분포
- 라플라스 분포
- 디랙 분포
- 혼합 분포들
- 3개의요소를 가진 가우시안 혼합 분포 <- 가우시안 혼합 모델 추정 가능
- 밀도추정에서 많이 쓰임
- 변수 변환
- 기존 확률변수를 새로운 확률 변수로 바꾸는 것
- 변환 $y=g(x)$와 가역성을 가진 $g$에 의해 정의되는 $x, y$ 두 확률변수를 가정할 때, 두 변수는 다음과 같이 상호 정의될 수 있음
- $p_x(x) = p_y(g(x))|det({\partial g(x) \above 1pt \partial x})|$
- $p_x(x) = p_y(g(x))|det({\partial g(x) \above 1pt \partial x})|$
정보이론
- 정보이론과 확률통계는 많은 교차점을 가짐(공통점이 많음)
- 확률통계는 기계학습의 기초적인 근간 제공
- 해당 확률 분포 추정
- 확률 분포 간의 유사성 정량화
- 정보이론 관점에서도 기계학습을 접근 가능
- 불확실성을 정량화 하여 정보이론 방법을 기계학습에 활용한 예
- 엔트로피, 교차 엔트로피, KL 발산(상대 엔트로피)
- 엔트로피, 교차 엔트로피, KL 발산(상대 엔트로피)
- 불확실성을 정량화 하여 정보이론 방법을 기계학습에 활용한 예
- 정보이론 : 사건(event)이 지닌 정보를 정량화할 수 있나?(불확실성을 통해 정량화한다. 불확실성은 확률적으로 작게 일어나는 것이다.)
- 정보이론의 기본 원리 -> 확률이 작을수록 많은 정보
- 자주 발생하는 사건보다 잘 일어나지 않는 사건의 정보량이 많음
- 자주 발생하는 사건보다 잘 일어나지 않는 사건의 정보량이 많음
- 정보이론의 기본 원리 -> 확률이 작을수록 많은 정보
- 자기 정보
- 사건(메시지) $e_i$의 정보량(이벤트의 정보량)
- 단위 : 로그의 밑이 2인 경우, 비트(bit) 또는 로그의 밑이 자연상수인 경우, 나츠(nat)
- $h(e_i) = -log_2P(e_i)$ 또는 $h(e_i) = -log_e P(e_i)$
- 이 자기정보 값이 높을수록 높은 정보량을 가짐.
- 확률변수 하나(이벤트 하나)만 보는 것이 자기 정보이다.
- 사건(메시지) $e_i$의 정보량(이벤트의 정보량)
- 엔트로피
- 확률변수 하나(이벤트 하나)만 보는 것이 아니라 확률변수가 가질 수 있는 모든 사건의 불확실성을 나타내는 것이 엔트로피이다.
- 확률변수 x의 불확실성을 나타내는 엔트로피
- 모든 사건 정보량의 기대 값으로 표현
- 이산확률분포
- 연속확률분포
- 동전의 앞뒤의 발생 확률이 동일할 경우, 동전의 발생 확률에 따른 엔트로피 변화
- 공평한 동전을 사용할 때에 가장 큰 엔트로피를 구할 수 있음. 즉 앞면이 나올 확률과 뒷면이 나올 확률이 동일할 때 가장 큰 불확실성이 발생하고, 가장 큰 엔트로피를 가짐.
- 무조건 앞면이 나올 확률이나 무조건 뒷면이 나올 확률일 경우 불확실성이 0이므로 가장 작은 엔트로피를 가짐.
- 동전 던지기 결과 전송에는 최대 1비트가 필요함을 의미
- 모든 사건이 동일한 확률을 가질 때. 즉, 불확실성이 가장 높은 경우, 엔트로피가 최고임
- 주사위가 윷(도개걸윷모)보다 엔트로피가 높은 이유?
- 윷은 2.0306 비트, 주사위는 2.585 비트
- 주사위는 모든 사건이 동일한 확률 -> 어떤 사건이 일어날지 윷보다 예측이 어려움 -> 주사위가 윷보다 더 무질서하고 불확실성이 큼 -> 엔트로피가 높음
- 교차 엔트로피(cross entropy) : 두 확률분포 P와 Q 사이의 교차 엔트로피
- 정보이론에서 많이 쓰이는 엔트로피. 두 확률분포가 얼마만큼의 정보를 서로 공유하고 있는지의 척도이다.
- 심층학습의 손실함수로 많이 사용됨
- 예측값과 실제값 둘의 확률분포가 얼마나 서로 공유하고 있는지를 척도로 나타낼 수 있으므로
- 식을 전개하면, $H(P, Q) = H(P) + \sum_{x} P(x)log_2 {P(x) \above 1pt Q(x)}$ -> KL발산
- 여기서 $P$를 데이터의 분포라 하면, 이는 학습 과정에서 변화하지 않음(P값은 고정이고, Q값을 조정시켜서 P에 대해 맞춤) -> 교차 엔트로피를 손실함수로 사용하는 경우, KL 발산의 최소화함과 동일(Q를 조정해서 손실함수를 최소화)
- KL 다이버전스(KL 발산)
- 두 확률분포 사이의 거리를 계산할 때 주로 사용.
- 확률분포 Q를 움직여서 움직이지 않는 데이터 확률분포P와 비슷하게 맞춰주는것.
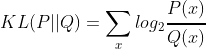
- 교차 엔트로피와 KL 다이버전스의 관계
- P와 Q의 교차 엔트로피 $H(P,Q) = H(P) + \sum_{x}log_2{P(x) \above 1pt Q(x)}$ = P의 엔트로피 + P와 Q간의 KL 다이버전스
- 즉, 가지고 있는 데이터 분포 $P(x)$와 추정한 데이터 분포 $Q(x)$간의 차이 최소화하는데 교차 엔트로피 사용
- 교차 엔트로피 적용 예
- 모델에 의해 5개의 값을 내놓으면(logistic value), 소프트맥스 값을 적용해 예측값을 만든다. (softmax value) 그 예측값과 실제값(Ground Truth)을 비교할 때 교차 엔트로피를 사용해서 정량화한다. 교차 엔트로피는 두 확률분포가 얼마나 비슷한지 정량화해서 보여준다. 교차 엔트로피(손실함수)를 낮춰서 실제 확률분포와 예측 확률분포가 같아지도록 정량화한다.(KL 다이버전스를 맞춰준다)
- 모델에 의해 5개의 값을 내놓으면(logistic value), 소프트맥스 값을 적용해 예측값을 만든다. (softmax value) 그 예측값과 실제값(Ground Truth)을 비교할 때 교차 엔트로피를 사용해서 정량화한다. 교차 엔트로피는 두 확률분포가 얼마나 비슷한지 정량화해서 보여준다. 교차 엔트로피(손실함수)를 낮춰서 실제 확률분포와 예측 확률분포가 같아지도록 정량화한다.(KL 다이버전스를 맞춰준다)
최적화
- 순수 수학 최적화와 기계 학습 최적화의 차이
- 순수 수학 최적화의 예 : 어떤 함수의 최저점을 찾아라.
- 기계 학습의 최적화는 단지 훈련집합이 주어지고, 훈련집합에 따라 정해지는 목적함수의 최저점으로 만드는 모델의 매개변수를 찾아야 함
- 주로 SGD(확률론적 경사 하강법) 사용
- 손실함수 미분하는 과정 필요 -> 오류 역전파 알고리즘
기계 학습의 최적화는 순수 수학 최적화보다 어려우며, 최적해가 보장되지 않는다.
- 손실함수 미분하는 과정 필요 -> 오류 역전파 알고리즘
기계 학습의 최적화는 순수 수학 최적화보다 어려우며, 최적해가 보장되지 않는다.
- 주로 SGD(확률론적 경사 하강법) 사용
매개변수 공간의 탐색
- 학습 모델의 매개변수 공간
- 특징 공간의 높은 차원에 비해 훈련집합의 크기가 작아, 참인 확률분포를 구하는 일은 불가능함. 즉 특징 공간의 모든 부분을 처리할 수 없으므로 특정 모델에 대해서만 한다는 것.
- 따라서 기계학습은 적절한 모델(가설)을 선택하고 목적함수를 정의하고, 모델의 매개변수 공간을 탐색하여 목적함수가 최저가 되는 최적점을 찾는 전략 사용
- 특징 공간에서 해야 하는 일을 모델의 매개변수 공간에서 하는 일로 대치한 셈
- 선형회귀 : 목적함수의 도함수=0을 풀어 구함 -> 최적 직선 방정식
- 퍼셉트론 : 스토케스틱 경사 하강법 -> 최적 가중치
- 딥러닝(파라미터의 개수가 더 많아짐) : 스토케스틱 경사 하강법 -> 최적 가중치
- 학습 모델의 매개변수 공간
- 특징 공간보다 배~수만 배 많은 차원을 가짐
- MNIST 인식하는 심층학습 모델은 784(28*28)차원 특징 공간, 수십만~수백만 차원의 매개변수 공ㄹ간
- 전역 최적해에 가까운 지역 최적해를 찾고 만족하는 경우 많음
- 손실함수 값의 미분값을 음수로 취한 것이 작아지도록 한다.
- 특징 공간보다 배~수만 배 많은 차원을 가짐
-
기계학습이 해야 할 일을 식으로 정의하면, $J(\Theta)$를 최소로 하는 최적해 $\widehat{\Theta}$을 찾아라. 즉, $\widehat{\Theta} = argmin_\Theta J(\Theta)$
- 최적화 문제 해결
- 낱낱탐색(exhaustive search) 알고리즘
- 차원이 조금만 높아져도 적용 불가능. 모든 가능한 파라미터 공간을 다 탐색함.
- 4차원 Iris에서 각 차원을 1000구간으로 나눈다면 총 1000^4개의 점을 평가해야함
- 무작위탐색(random search)알고리즘
- 아무 전략이 없는 순진한 알고리즘
- 낱낱탐색(exhaustive search) 알고리즘
- 기계학습이 사용하는 전형적인 알고리즘
- 입력 : 훈련집합 X와 Y
- 출력 : 최적해 $\widehat{\Theta}$
- 난수를 생성하여 초기해 $\widehat{\Theta}$를 설정한다.
- repeat
- $J(\Theta)$가 작아지는 방향 $d\Theta$를 구한다. // 목적함수가 작아지는 방향을 주로 미분으로 찾아냄
- $\Theta = \Theta + d\Theta$
- until(멈춤 조건)
- $\widehat{\Theta} = \Theta$
미분
- 미분에 의한 최적화
- 1차 도함수 $f’(x)$는 함수의 접선의 기울기(경사), 즉 함수의 값이 커지는 방향을 지시함. -> 즉 마이너스를 붙이면 $-f’(x)$방향에 목적함수의 최저점이 존재
- 위의 알고리즘에서 $d\Theta$로 $-f’(x)$를 사용함 <- 경사 하강 알고리즘의 핵심 원리
- 편미분
- 변수가 복수인 함수의 미분
- 미분 값이 이루는 벡터를 경사도(변화도)라고 함
- 기계 학습에서 편비문
- 매개변수 집합 $\Theta$은 복수 매개변수이므로 편미분을 사용
- 경사도는 편미분들의 요소를 가지고 있으므로!
- 독립변수와 종속변수의 구분
- $y = wx + b$에서 일반적으로 x는 독립변수, y는 종속변수
- 기계 학습에서 예측 단계를 위한 해석은 무의미함.
- 최적화는 예측 단계가 아니라 학습 단계에 필요
- $J(\Theta) = {1 \above 1pt n}\sum_{i=1}^{n}(f_\Theta(x_i)-y_i)^2$
- $\Theta$가 독립변수이고 $error = J(\Theta)$라 하면 error가 종속변수임
- 즉 세타값을 잘 조정해서 에러값을 최적화해야함.
- 연쇄법칙(chain rule)
- 합성함수 $f(x) = g(h(x))$와 $f(x) = g(h(i(x)))$의 미분
- $f’(x)=g’(h(x))h’(x)$
- $f’(x)=g’(h(i(x)))h’(i(x))i’(x)$
- 다층 퍼셉트론은 합성함수
- 출력(결과값)은 합성함수로 겹겹이 쌓여서 나옴. (여러 레이어를 통과하기 때문에)따라서 이 값의 미분값을 구하기 위해서는 합성함수의 미분, 즉 연쇄법칙을 사용해야 함.
- 출력(결과값)은 합성함수로 겹겹이 쌓여서 나옴. (여러 레이어를 통과하기 때문에)따라서 이 값의 미분값을 구하기 위해서는 합성함수의 미분, 즉 연쇄법칙을 사용해야 함.
- 야코비안 행렬(Jacobian matrix)
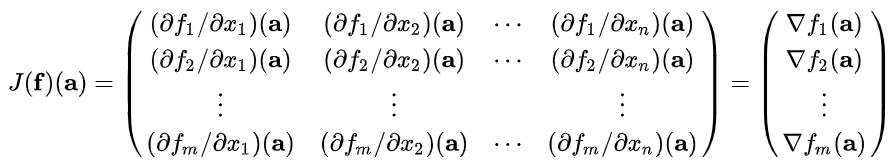
- 각 요소를 1차 편미분한 것
- 헤세 행렬(Hessian matrix)
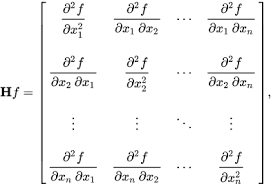
- 각 요소를 2차 편미분한 것. 2차 편도함수
- 각 요소를 2차 편미분한 것. 2차 편도함수
경사 하강 알고리즘
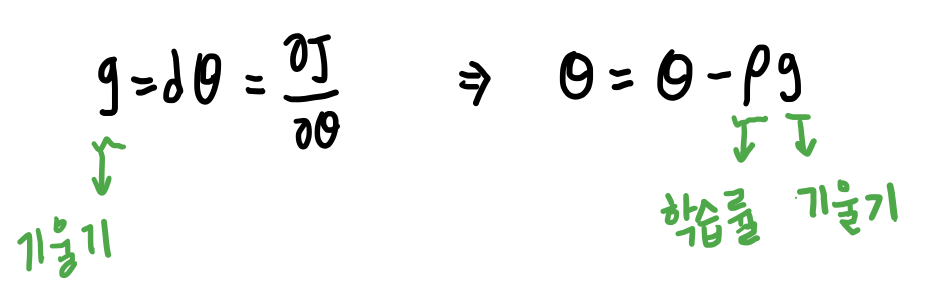
- 손실함수를 매개변수 세타로 미분한 것이 기울기.
- 함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 반복적으로 이동하여 최소값에 도달

- 집단(무리, batch) 경사 하강 알고리즘
- 샘플의 경사도를 구하고 평균한 후 한꺼번에 갱신
- 훈련집합 전체를 다 봐야 갱신이 일어나므로 학습 과정이 오래 걸리는 단점. 갱신을 한번 하기 위해 데이터셋을 다 집어넣고 나온 손실함수를 또 미분해서 갱신하기 때문에.
- 일반적으로 더 많이 쓰이는 확률론적 경사 하강(SGD) 알고리즘
- 한 샘플 혹은 작은 집단(무리, mini batch)의 경사도를 계산한 후 즉시 갱신
- mini batch : 3~6번째 줄을 한 번 반복하는 일을 epoch라 부름.

- 경사 하강 알고리즘 비교
- 집단 경사 하강 알고리즘 : 정확한 방향으로 수렴. 느림
- 확률론적 경사 하강 알고리즘 : 수렴이 다소 헤맬 수 있음(지그재그). 빠름.
- 추가 경사 하강 알고리즘들 비교
- 확률론적 경사 하강법 + 추가 제어 알고리즘
- 확률론적 경사 하강법 + 추가 제어 알고리즘
실습
Deep Learning Hardware
- CPU, GPU, TPUs
- CPU : 코어 수가 작고 각각의 코어가 더 빠르고 연산력 우월. 연속적인 task에 강점
- GPU : 코어 수가 많고 각각의 코어가 더 멍청. 병렬적인 task에 강점(ex: 행렬곱셈). 딥러닝 시 CPU와 세배정도의 우월한 성능을 보임.
- TPU : 구글에서 사용하는 용어. 딥러닝 연산에 특화된 하드웨어.
- Programming GPUs
- CUDA(NVIDA only) : 이 툴은 C와 유사한 형태로 쓰인 코드로 GPU상에서 직접적인 연산 가능. 엔비디아에서만 사용 가능
- OpenCL : 쿠다랑 비슷하지만 어느 장비에도 다 사용 가능.
- HIP : 쿠다 코드를 AMD GPU에서 사용할 수 있게 함
- Udacity CS 344
- CPU/GPU Communication
- 모델은 GPU에 있다.
- 데이터는 하드디스크에 있디.
- 하드 디스크에 있는 데이터를 GPU로 보내서 모델을 돌려야 한다. bottleneck의 해결방법으로 HDD대신 SSD사용, RAM에 데이터 옮기기 등이 있다.
Deep Learning Software
- The point of deep learning frameworks
- 새로운 아이디어를 빠르게 개발하고 테스트할 수 있다.
- 그래디언트를 자동으로 계산해준다.
- GPU에서 빠르게 돌아간다.
- PyTorch and TensorFlow
- PyTorch
- Tensor: 텐서를 사용(numpy 패키지). 어레이와 비슷하고 GPU상에서 돌아감
- Autograde : 패키지. 텐서를 사용해서 연산그래프를 쌓고, 그래디언트를 자동으로 계산하는 패키지
- Module : 뉴럴 네트워크의 레이어. 연산의 중간 결과를 저장하거나 가중치들을 갖고 있는 것.
- TensorFlow
- Neural Net
- Optimizer
- Loss
- Keras : High Level wrapper
- @tf.function : compile sttic graph
- Pretrained Model
- Distributed Version 적용 가능
- PyTorch
- Static and Dynamic computation graphs
- static graphs : 연산을 합쳐서 한번에 할 수 있다. 그래프가 일단 쌓아지면 코드 없이 돌아갈 수 있다. Tensorflow에서 사용. Pytorch에서 사용하고 싶다면 Caffe2 사용. ONNX로도 파이토치 모델을 사용가능.
- dynamic graphs : 연산과 동시에 그래프가 쌓이기 때문에 코드가 계속해서 필요하다. Tensorflow, Pytorch.
- Recurrent network
- Recursive network
- Modular Network