
[프로그래머스인공지능스쿨]AWS를 활용한 인공지능 모델 배포
1. 클라우드 기초
Before Cloud computing
과거에는 인터넷 환경에서 서비스를 제공하기 위해 서비스 제공자는 서비스 호스팅에 필요한 모든 것을 직접 구축해야 했다.
데이터 센터를 처음 구축할 때 서비스 아키텍처나 자원 예상 사용량 등을 고려해 구축했다.
- 데이터 센터(물리적 공간)
- 서버, 저장소
- 네트워크 방화벽, 보안
- 운영체제, 기타 개발도구
- 전기, 온도, 습도 관리
- 운영/관리 인력
하지만 서버를 직접 구축하고 운영하는 자원과 인력 비용이 크고 운영 상황의 변화에 능동적으로 대응하기가 어려움.
회사나 조직이 직접 모든 것을 구축하고 운영하지 않도록 도와주는 IDC 등장
IDC는 Internet Data Center의 줄임말로 서버 운영에 필요한 공간, 네트워크, 유지 보수 등의 서비스를 제공함
IDC 입주자가 직접 서버를 구입해 들어오기도 하지만 불필요한 또는 유휴 자원이 발생하기 때문에 IDC에서 직접 서버를 임대해주기도 함
서버 임대를 통해 자원을 효율적으로 이용하고 비용을 줄일 수 있었지만 대부분의 IDC 서버 임대는 계약을 통해 일정 기간 임대를 하는 유연성이 떨어지는 구조
Backgrounds of Cloud computing
인터넷 사용자가 크게 증가하고 다양한 서비스를 제공하게 되면서 필요한 때에 필요한 만큼 서버를 증설하기 원하는 온디맨드 수요 증가
제 4차 산업혁명 시대에서 IT기술과 인프라는 빠르게 발전하면서 기존의 서버 구축이나 운영 방식으로는 적절한 시간에 필요한 서비스를 사용자에게 제공하기 어려움
개발 서버 지원 사용률은 평균 10~15%였으며 다른 여러 사용자와 공유함으로 사용률을 향상시켜 자원의 효율적인 활용과 이를 통한 비용 절감을 추구하고자 하였음
사용자 :
- “사용자 접속량이 늘어나 컴퓨팅 수요가 증가할 때는 오토 스케일링이 필요해요!”
- “평상시에 사용하지 않는 유휴 자원은 비용에서 빼주세요!”
- “필요한 시점에 바로 사용할 수 있게 운영체제나 필요한 소프트웨어는 미리 설치해주세요!”
Cloud Computing
클라우드라고 부르기도 하며 “인터넷 기반 컴퓨팅의 일종”
언제 어디서나 필요한 만큼의 컴퓨팅 자원을 필요한 시간만큼 인터넷을 통하여 활용할 수 있는 컴퓨팅 방식
2006년 아마존이 클라우드를 통한 저장공간 및 연산 자원 제공 서비스인 S3와 EC2를 개시하면서 본격적인 클라우드 컴퓨팅 시대 시작
- AWS : AWS는 클라우드 컴퓨팅을 클라우드 서비스 플랫폼에서 컴퓨팅 파워, DB 저장공간, 애플리케이션 및 기타 IT 자원을 필요에 따라 인터넷을 통해 제공하고 사용한 만큼만 비용을 지불하는 것으로 정의
4차 산업혁명 시대에서 빅데이터의 수집, 저장, 분석을 위한 방대한 컴퓨팅 자원과 인공지능 개발을 위한 고성능 컴퓨터를 스타트업이나 중소기업이 처음부터 모든 것을 별도로 구입하지 않고도 적은 비용으로 빠르게 필요한 IT 환경 마련 가능
Features of Cloud Computing
클라우드 컴퓨팅은 속도, 접근성, 확장성, 생산성, 보안 및 안전성, 측정가능성 등의 장점을 가짐
특히 인공지능 서비스 제공 시에 도커와 같은 가상화 기술을 통해 GPU 활용과 소프트웨어 설치 및 배포 등의 작업에 비용과 시간 절감
- 속도-주문형 셀프서비스
- 클라우드 제공자와 별도의 커뮤니케이션 없이 원하는 클라우드 서비스를 바로 이용 가능
- 자기가 원할 때, 원하는 상황에 원하는 서비스를 선택해서 주문 가능
- 접근성
- 인터넷을 통해 사용자의 위치, 시간과 관계없이 어떤 디바이스로도 접근 가능
- 확장성
- 갑작스러운 이용량 증가나 변화에 신속하고 유연하게 추가 확장이 가능
- 생산성
- 하드웨어, 소프트웨어 설치에 들어가는 시간과 비용 절감으로 핵심업무에 집중
- 보안, 안정성
- 클라우드 공급자가 전체적으로 보안이나 안정성에 대해 준비
- 측정가능성
- 분초 단위로 사용자가 클라우드 서비스를 사용한 만큼만 계량하여 과금
- 분초 단위로 사용자가 클라우드 서비스를 사용한 만큼만 계량하여 과금
클라우드 컴퓨팅 운용 모델
클라우드 컴퓨팅은 구축 및 배포 유형에 따라 퍼블릭(Public), 프라이빗(Private), 하이브리드(Hybrid) 클라우드 세 가지 형태로 구분
- 퍼블릭(Public)
- 서비스 유지를 위한 모든 인프라와 IT 기술을 클라우드에서 사용
- AWS, GCP, Azure와 같은 외부 클라우드 컴퓨팅 사업자가 IT자원을 소유하고 인터넷을 통해 제공
- IT관리 인력이나 인프라 구축 비용이 없는 경우에 유용
- 프라이빗(Private)
- 고객이 자체 데이터센터에서 직접 클라우드 서비스를 구축하는 형태
- 가상화 기술로 물리적인 컴퓨팅을 내가 원하는 만큼 쪼개서 가상화된 형태로 제공하여 유연하게 사용 가능
- 내부 계열사나 고객에게만 제공하여 인프라 확충은 쉬우나 IT 기술 확보가 어려운 단점이 있음(내부 인프라망에서만 서비스를 제공하기 위해 주로 사용)
- 보안이 좋고(폐쇄적임) 커스터마이제이션 가능하며 글로벌 클라우드 사업자가 IT기술인 패키지형태로 판매하기도 함
- 하이브리드(Hybird)
- 퍼블릭과 프라이빗을 둘다 사용하기 위한 클라우드 운용 방식
- 고객의 핵심 시스템은 내부에 두면서도 외부의 클라우드를 활용하는 형태
- IT 기술은 클라우드에서 받고 서비스 유지를 위한 인프라는 고객의 것을 혼용
- 퍼블릭의 경제성과 프라이빗의 보안성을 모두 고려
- 여러개의 퍼블릭 클라우드를 사용하거나 여러개의 프라이빗 클라우드를 사용하는 것도 하이브리드라고 하는데, 최근에 멀티클라우드, 분산형클라우드와 같이 클라우드의 여러가지 개념이 도입되었다.
- 멀티클라우드 : 아마존만 쓰는게 아니라 네이버의 클라우드, 구글의 클라우드를 공유하는 형태로 서비스 제공에 사용하는 형태가 있다. 특정 클라우드 사업자에 너무 의존하지 않게 된다.
- 분산형 클라우드 : 블록체인과 같이 클라우드 자원을 분산적으로 끌어다 사용하는 형태
클라우드 서비스 제공 모델
클라우드 서비스 제공 방식에 따라 IaaS, PaaS, SaaS 세 가지 형태로 구분
- On-Premises : A부터 Z까지 모든것을 다 구축하고 관리하는 형태. 서버를 위한 Application, Data, Runtime, Middleware, OS, Virtualization, Servers, Storage, Networking을 모두 구축하고 관리하는 것이다.
- 직접 차 사서 운전하기
- Iaas : 인프라 부분(irtualization, Servers, Storage, Networking)만 클라우드에서 빌려서 한다. Application, Data, Runtime, Middleware, OS는 직접 관리한다.
- 차를 빌려서 타기
- Paas : 인프라 + 플랫폼 부분(Runtime, Middleware, OS, Virtualization, Servers, Storage, Networking)을 클라우드에서 빌려서 한다. Application, Data만 직접 관리한다.
- 택시 타기
- SaaS : Application, Data, Runtime, Middleware, OS, Virtualization, Servers, Storage, Networking을 모두 클라우드에서 빌려서 한다. 최근 인공지능 모델의 API 서비스들은 SaaS형태로 많이 제공되고 있다.
- 버스 타기
- 버스 타기
클라우드 서비스 제공 사업자
AWS, GCP, Azure, NCP등 다양한 클라우드 벤더들이 클라우드 서비스를 제공
AWS Cloud Computing
AWS는 인프라와 기초 서비스 뿐만 아니라 사용자 니즈에 맞는 다양한 애플리케이션 서비스를 제공
2. 실습 : AWS & 실습 환경 세팅
AWS 계정 가입
https://aws.amazon.com/ko/ 접속
해외결제 가능한 카드 결제를 등록해야 회원가입이 가능
1달러가 결제될텐데 놀라지 말고..! 결제 가능한 카드인지 확인하는 절차라 다시 결제가 취소된다.
신규 회원은 프리티어 서비스에 대해 12개월 무료로 사용 가능
프리티어 서비스가 여러가지 있는데, 12개월 무료는 EC2 서비스!
EC2 생성 & Security group 설정
AMI 선택
AWS Management Console 페이지에 들어간다.
딥러닝 AMI이 설치된 EC2를 생성하여 필요 개발 환경 사전 세팅을 진행할 것이다.
EC2를 사용하여 가상 머신 시작을 클릭한다.
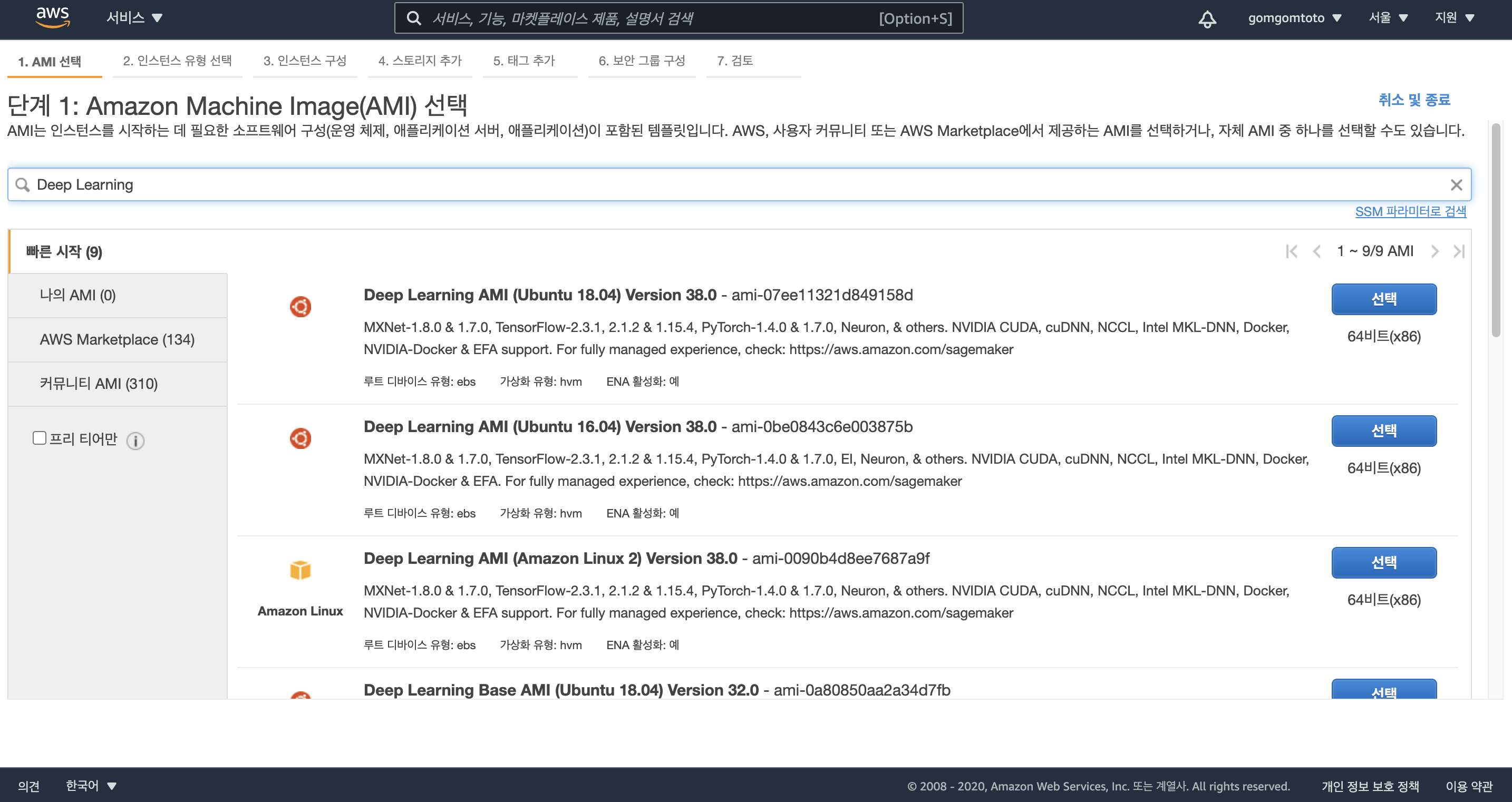
검색 부분에 Deep learning을 입력한다.
맨 위의 것을 선택했다.(Deep Learning AMI (Ubuntu 18.04) Version 38.0 - ami-07ee11321d849158d)
-> 나중에 피눈물 흘리지 말고 그 아래 버전 Deep Learning AMI (Ubuntu 16.04) Version 38.0이걸 깔자…ㅠㅠㅠ
인스턴스 유형 선택 & 보안 그룹 설정
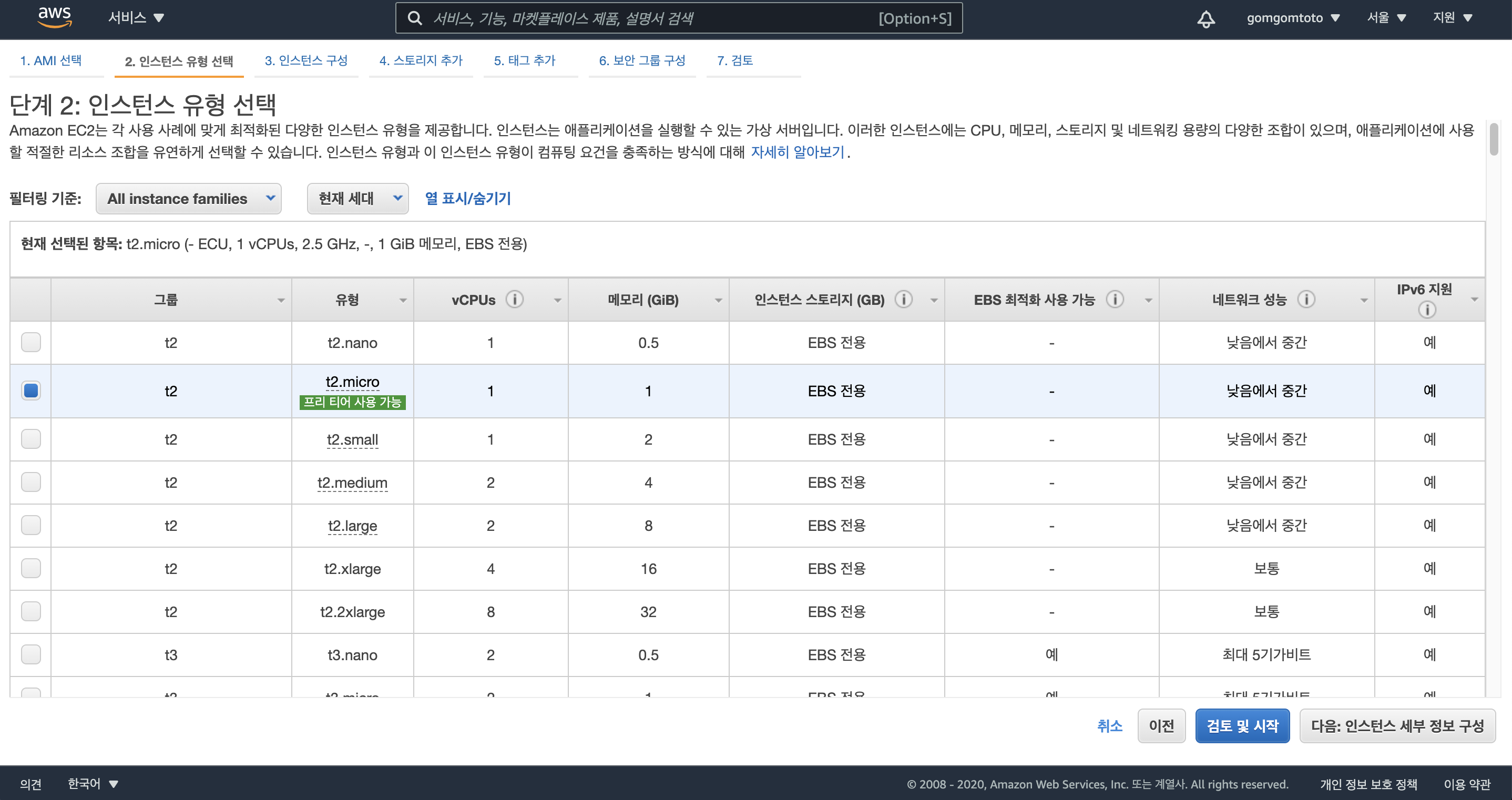
프리티어인 t2.micro 또는 computing에 최적화된 가장 저렴한 c5.large 인스턴스 유형 선택한 후 “다음: 인스턴스 세부정보 구성” 클릭
c5.large같은 경우 시간당 120~130원정도 청구됨! 돈을 지불하길 원치 않으면 t2.micro 선택
주의 : 인스턴스 타입에 따라 과금이 발생할 수 있음. 사용하지 않을 때는 “중지”또는 “종료”
“단계6: 보안그룹 구성”이 나올 때까지 계속 다음 클릭
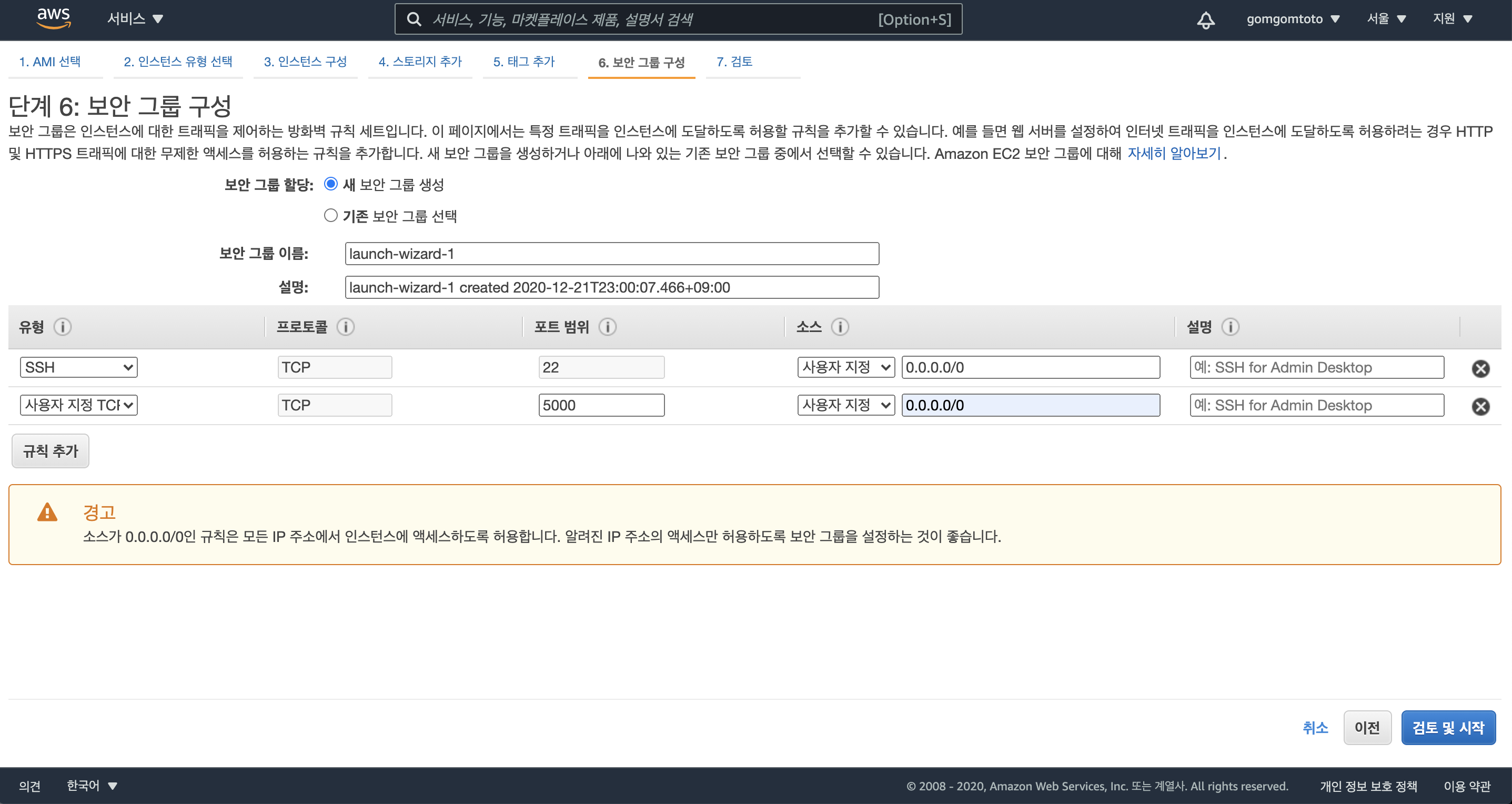
원격으로 API 서버에 접근/호출할 수 있도록 사용자 설정 포트를 새로 생성(ex. 포트범위:5000, 소스 0.0.0.0/0)후 검토 및 시작 버튼 클릭
키 페어 생성 & 인스턴스 시작 검토
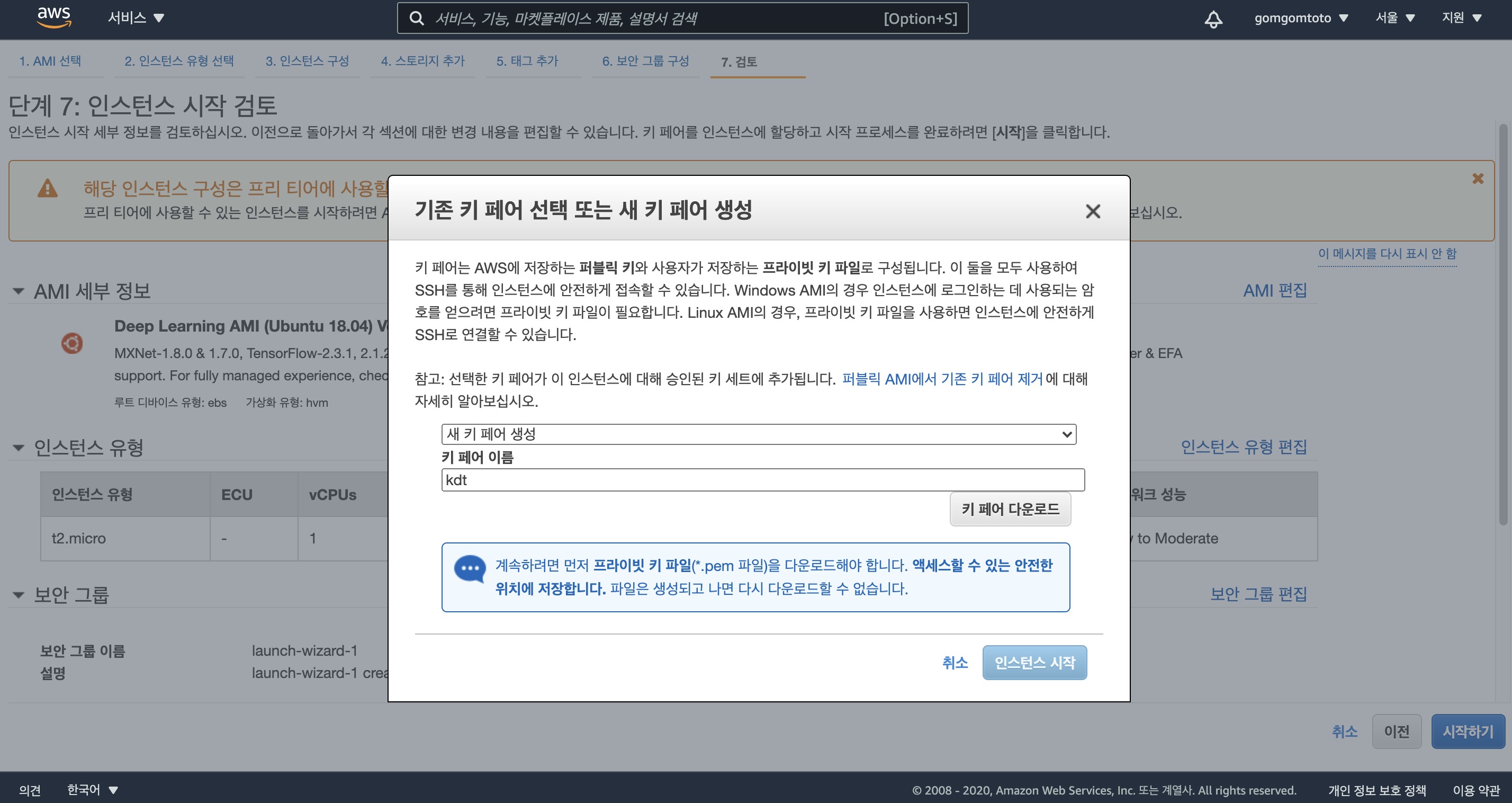
우측 하단의 “시작하기”버튼을 누르면 다음과 같은 창이 뜬다.
보안을 위한 키 페어 생성을 위해 키 페어 이름을 입력하고 (ex. kdt)”키 페어 다운로드”를 클릭하여 키 페어 다운로드.
다운로드한 키 페어는 이후 인스턴스에 접속하기 위해 필요
인스턴스 시작 버튼 클릭.
인스턴스 생성 확인
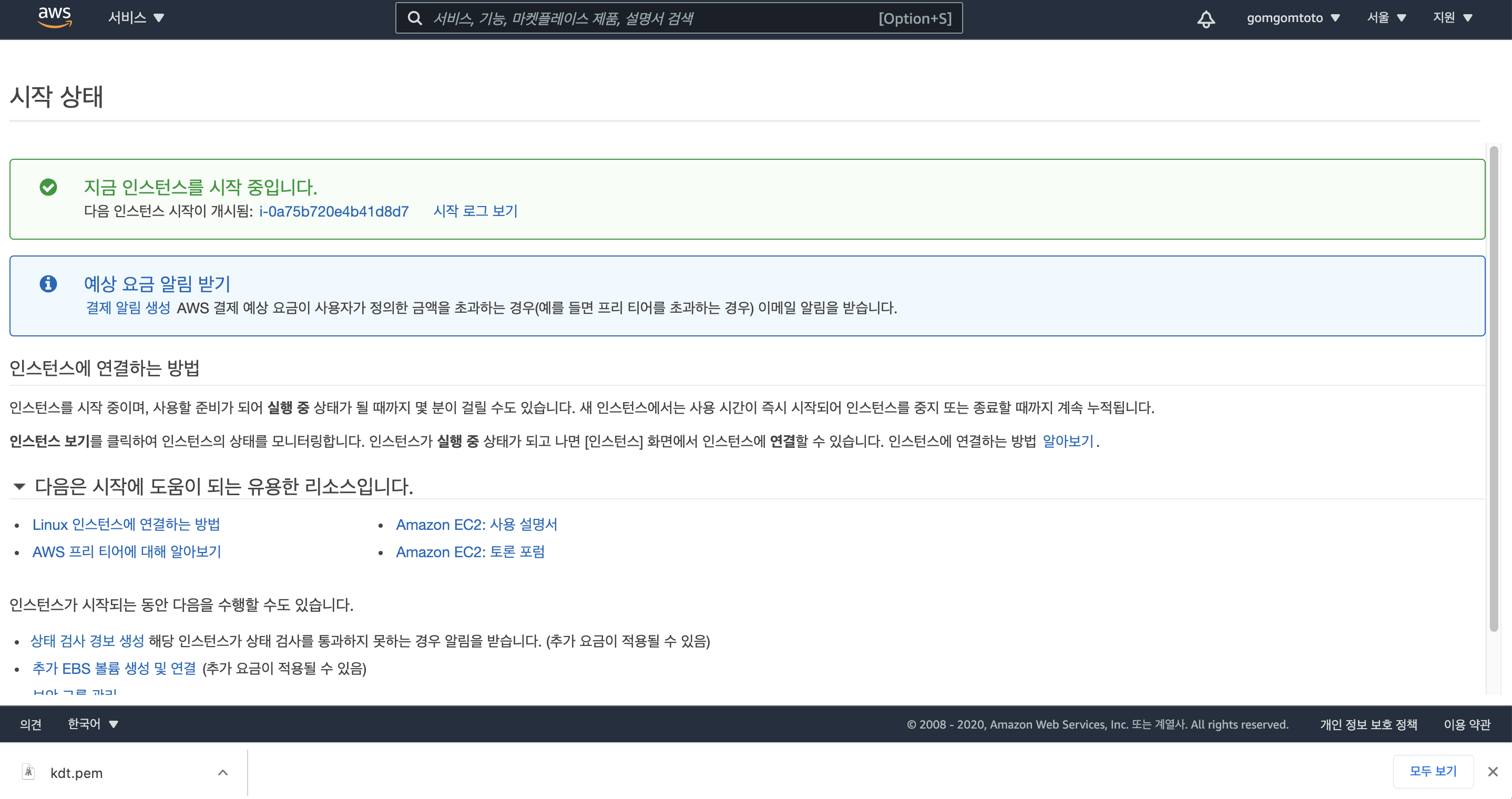
다음과 같이 인스턴스 ID(i-0a75b720e4b41d8d7)가 생성된 것을 볼 수 있다.
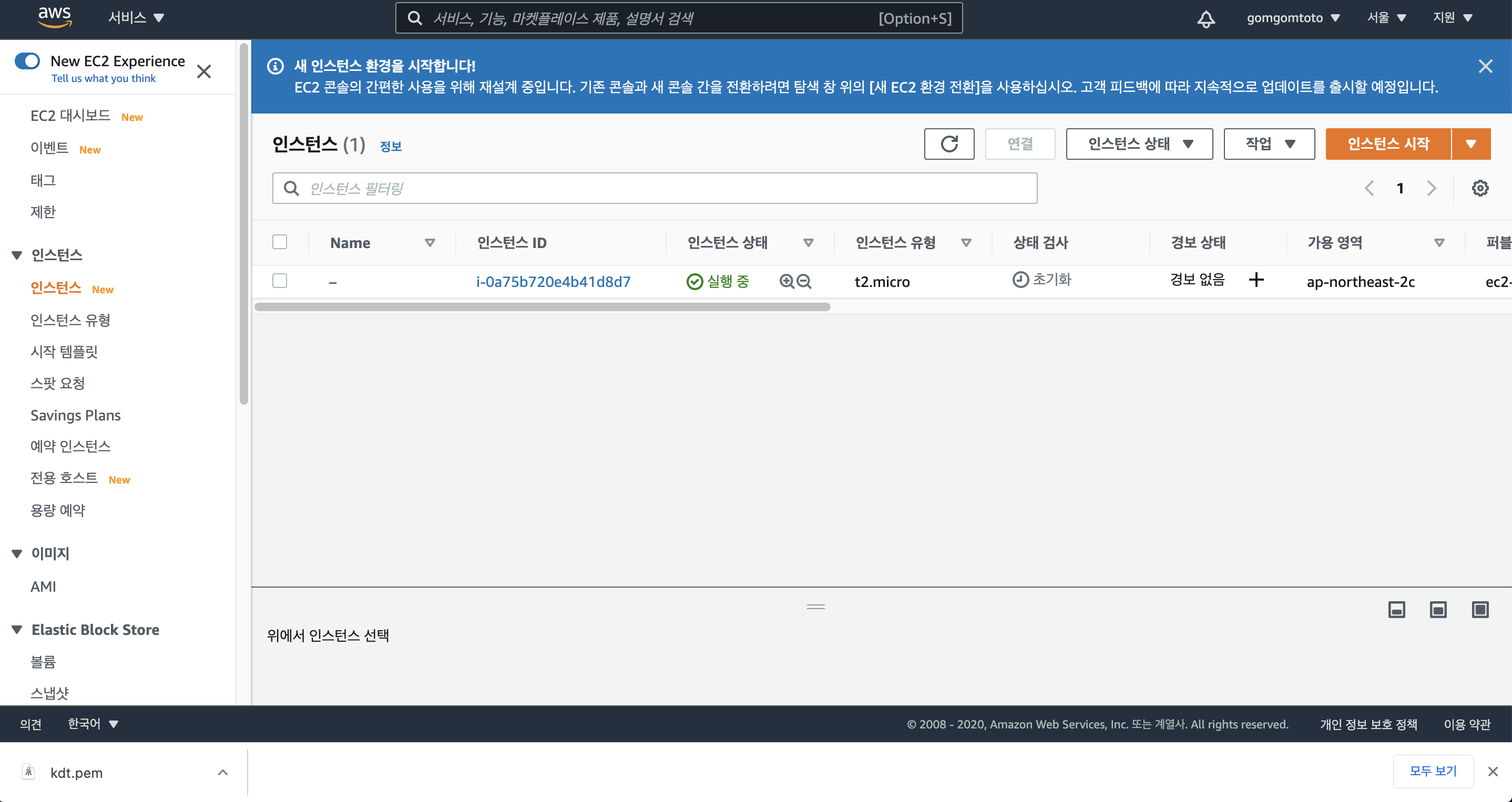
우측 하단의 “인스턴스 보기”를 클릭해 현재 인스턴스의 상태를 볼 수 있다.
탄력적 IP 설정
탄력적 IP 생성
인스턴스를 중지 또는 종료 후 다시 시작하거나 생성하게 되면 기존 퍼블릭 IP가 변경됨.
퍼블릭 IP를 고정으로 사용하고 싶을 때 탄력적 IP 주소를 할당할 수 있으나 추가 과금 발생.
왼쪽 카테고리에서 네트워크 및 보안 > 탄력적IP를 클릭
탄력적 IP 생성을 위해 “탄력적 IP 주소 할당” 클릭
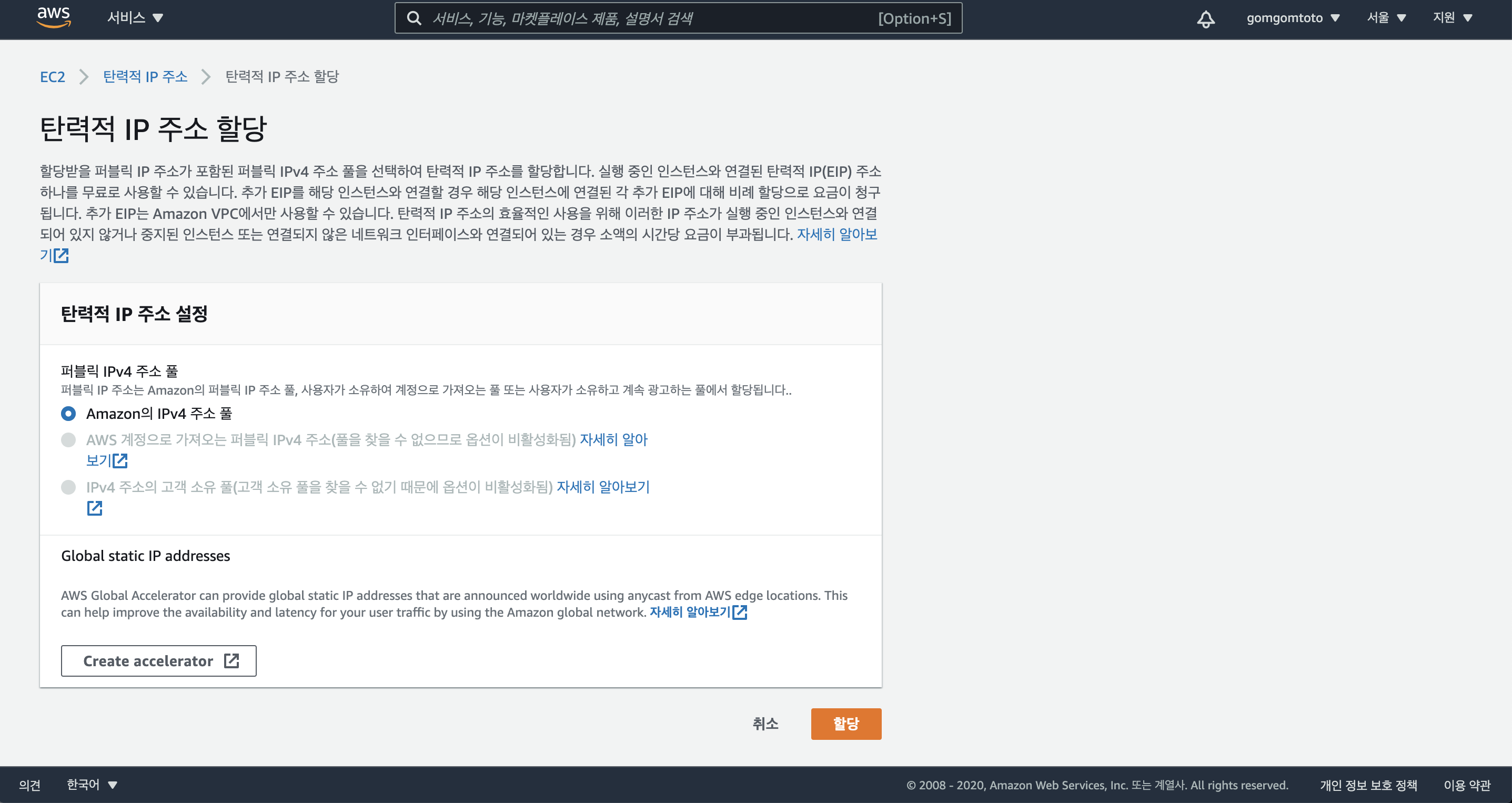
고정 IP를 받을 수 있는 창이 뜬다. “할당”을 클릭한다.
탄력적 IP를 인스턴스에 연결
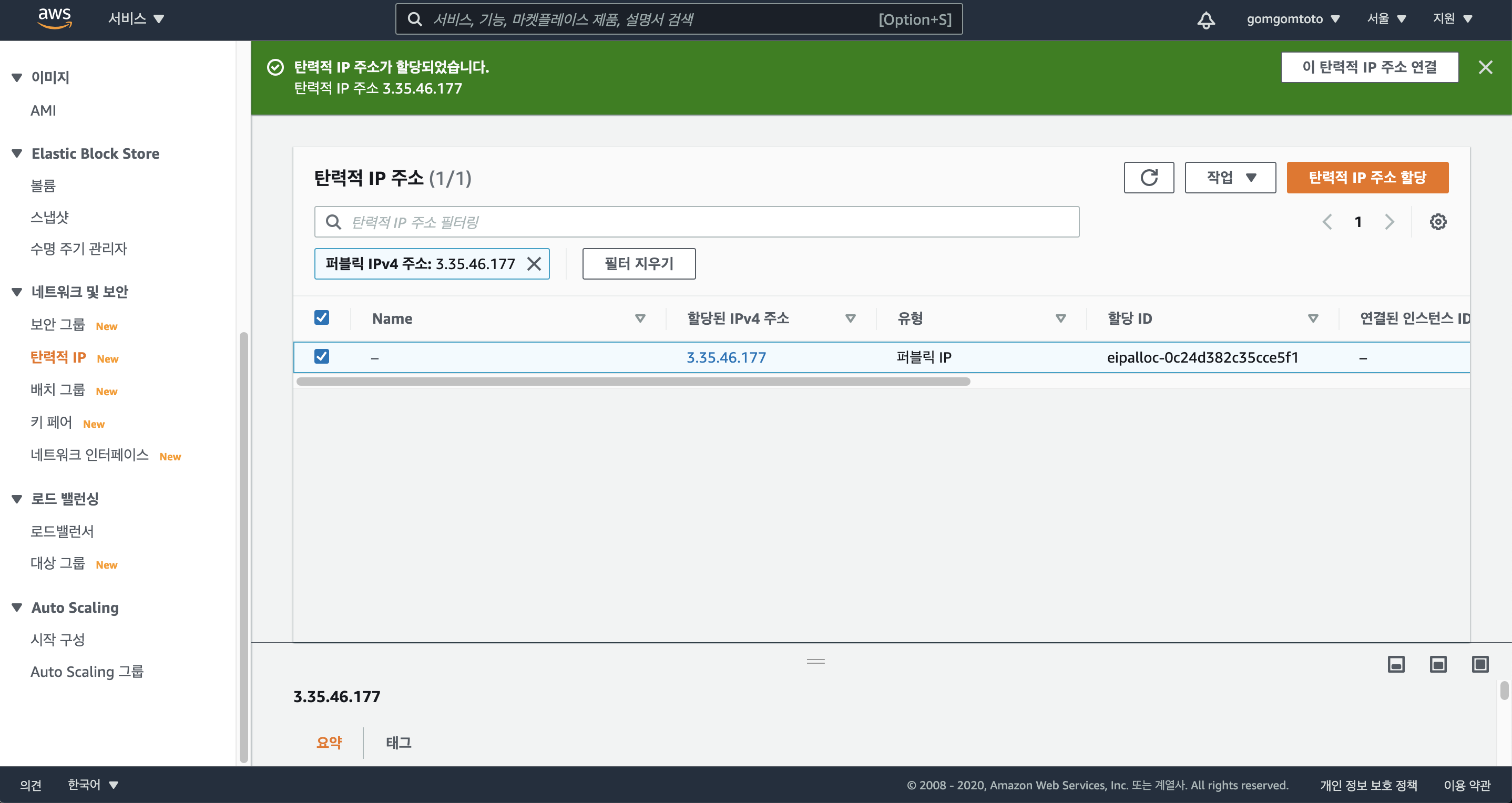
“할당”을 클릭하면 다음과 같은 페이지로 이동한다.
할당 받은 IP는 3.35.46.177로 할당받았다.
이렇게 생성한 탄력적 IP를 기 생성한 인스턴스의 IP 주소로 사용하기 위해 연결한다.
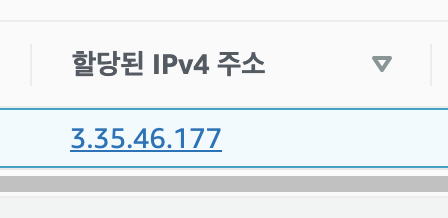
우선, 할당된 IPv4주소인 3.35.46.177을 클릭한다.
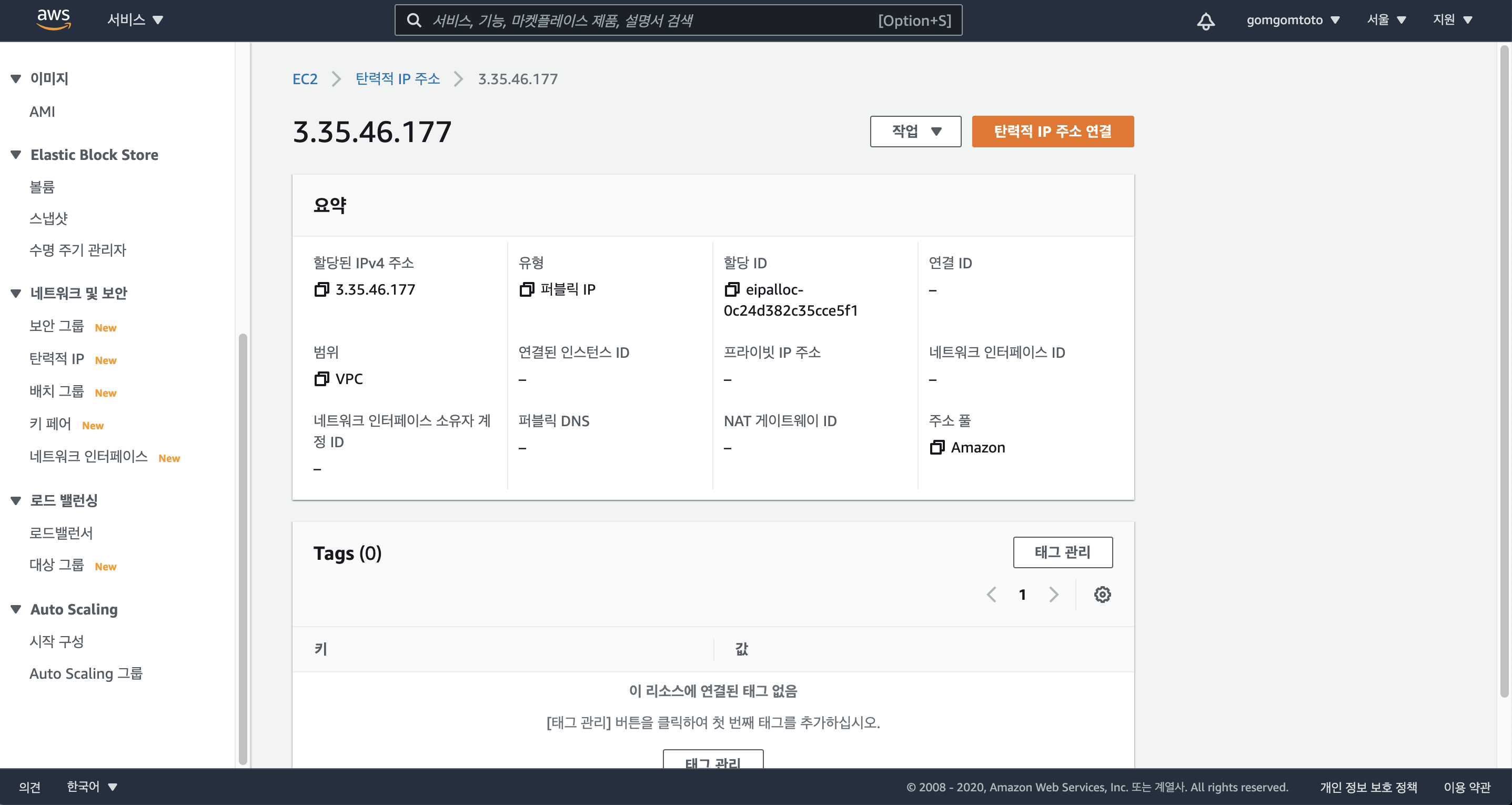
그럼 이런 페이지가 뜬다. “탄력적 IP주소 연결”을 클릭한다.
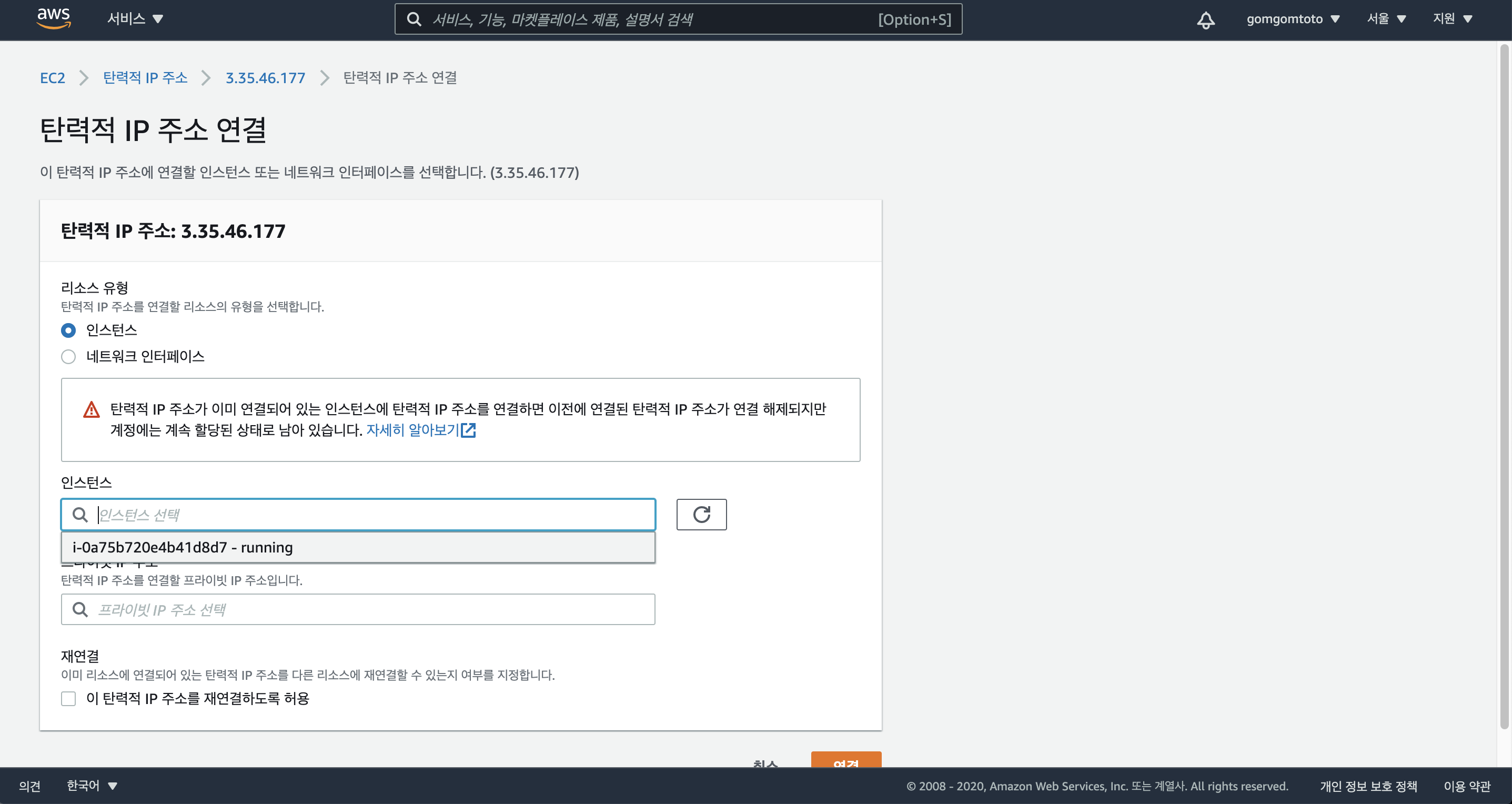
인스턴스를 현재 내가 생성한 인스턴스로 선택해준다.
“연결”을 클릭한다.
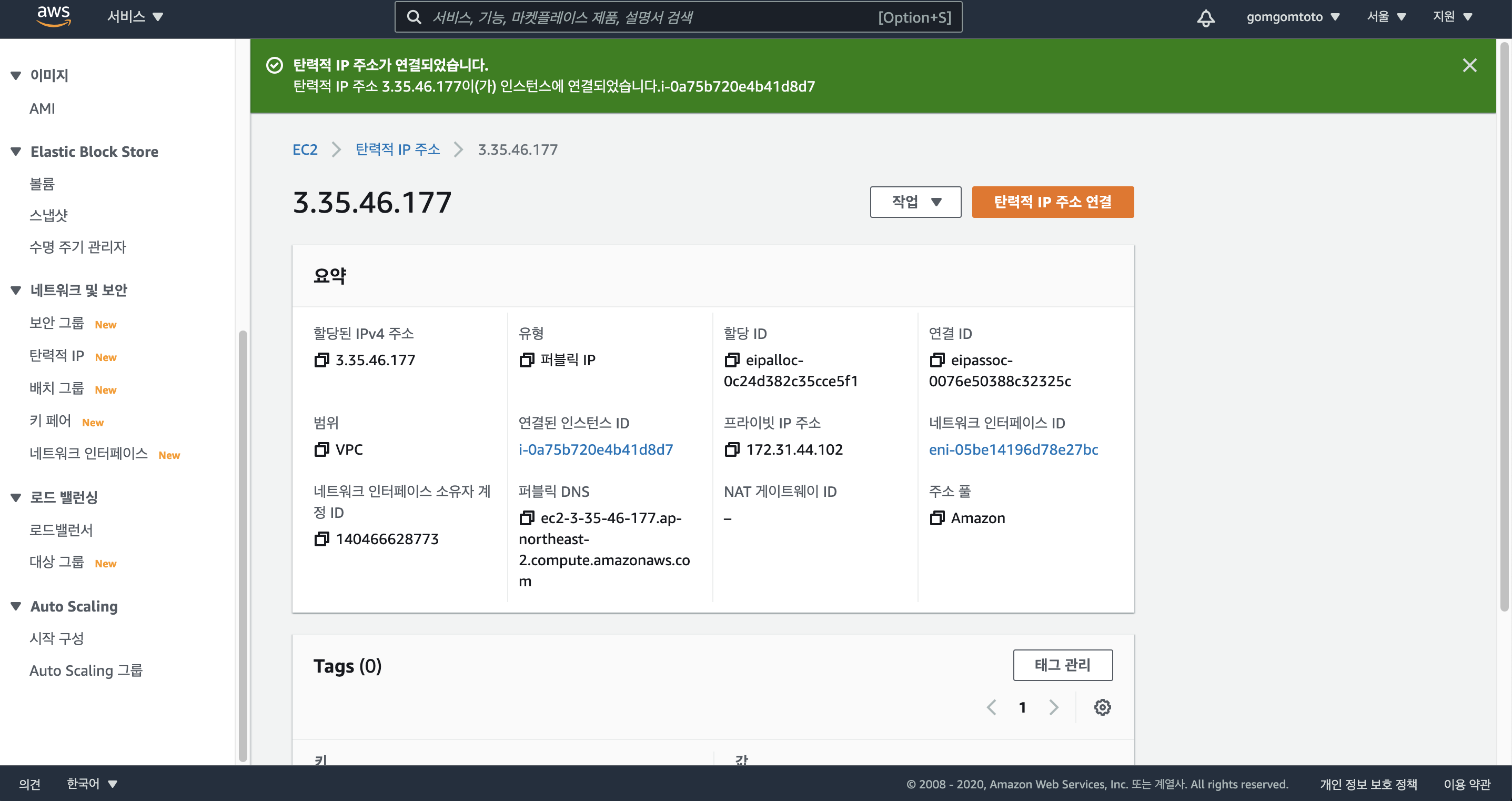
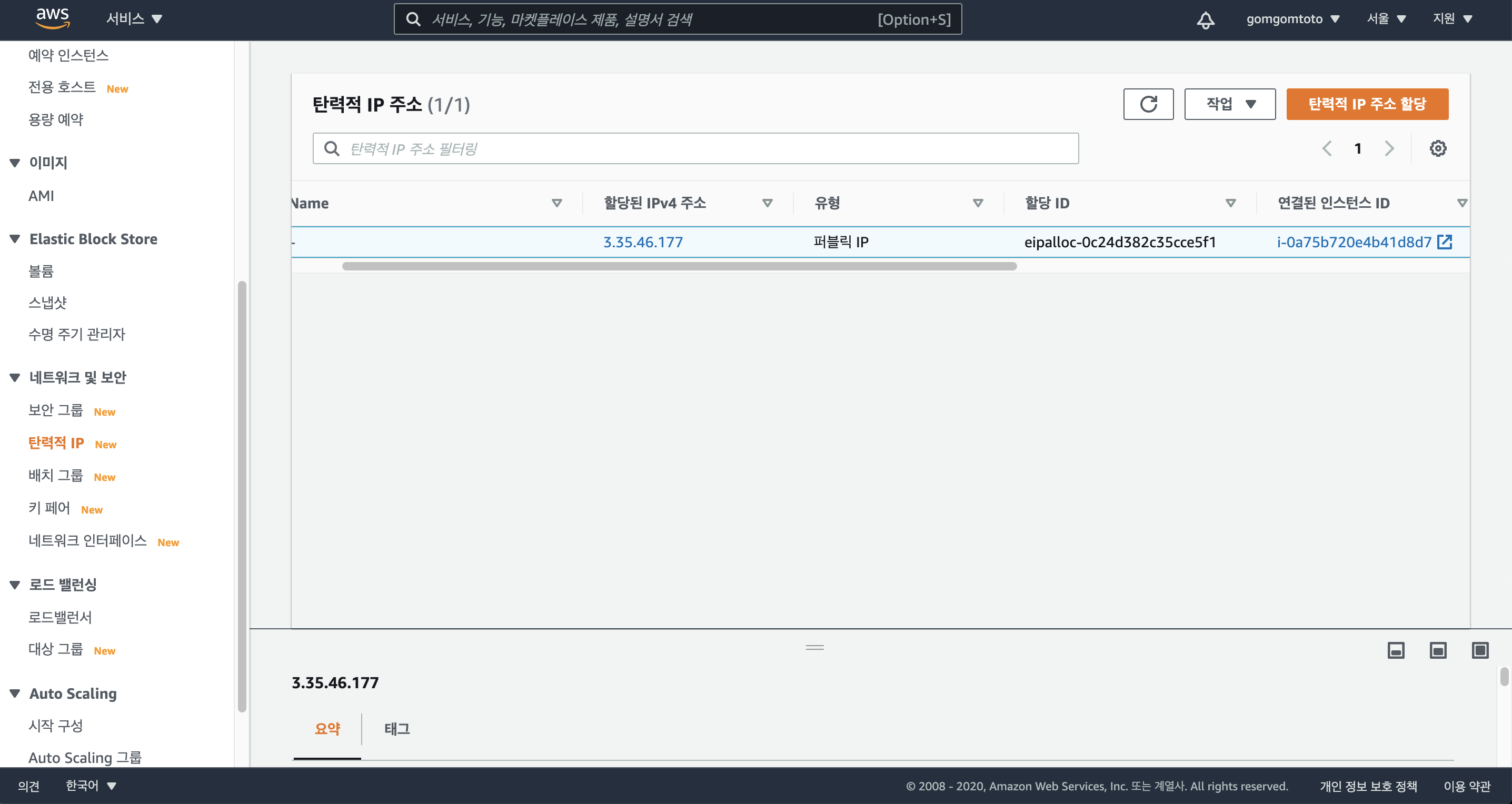
다음과 같이 현재 연결되 인스턴스 ID를 확인할 수 있다.
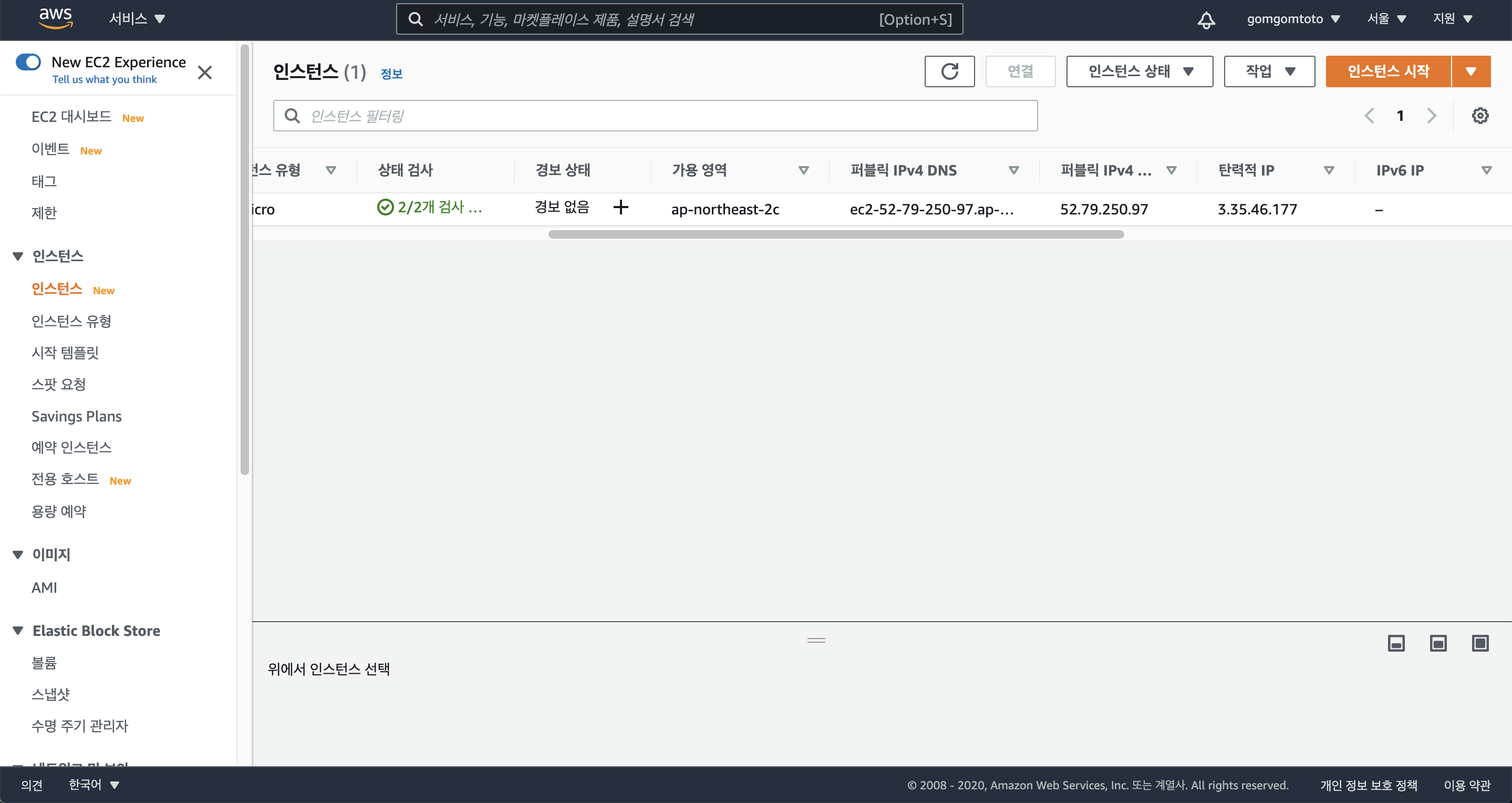
인스턴스 페이지로 가보면 퍼블릭 IP주소가 탄력적 IP주소로 똑같이 맞춰진 것을 확인할 수 있다.
VS Code로 환경 테스트
인스턴스 연결 초기화(initialization)
다운로드 받은 키 페어가 있는 위치에서 AWS 가이드에 따라 진행
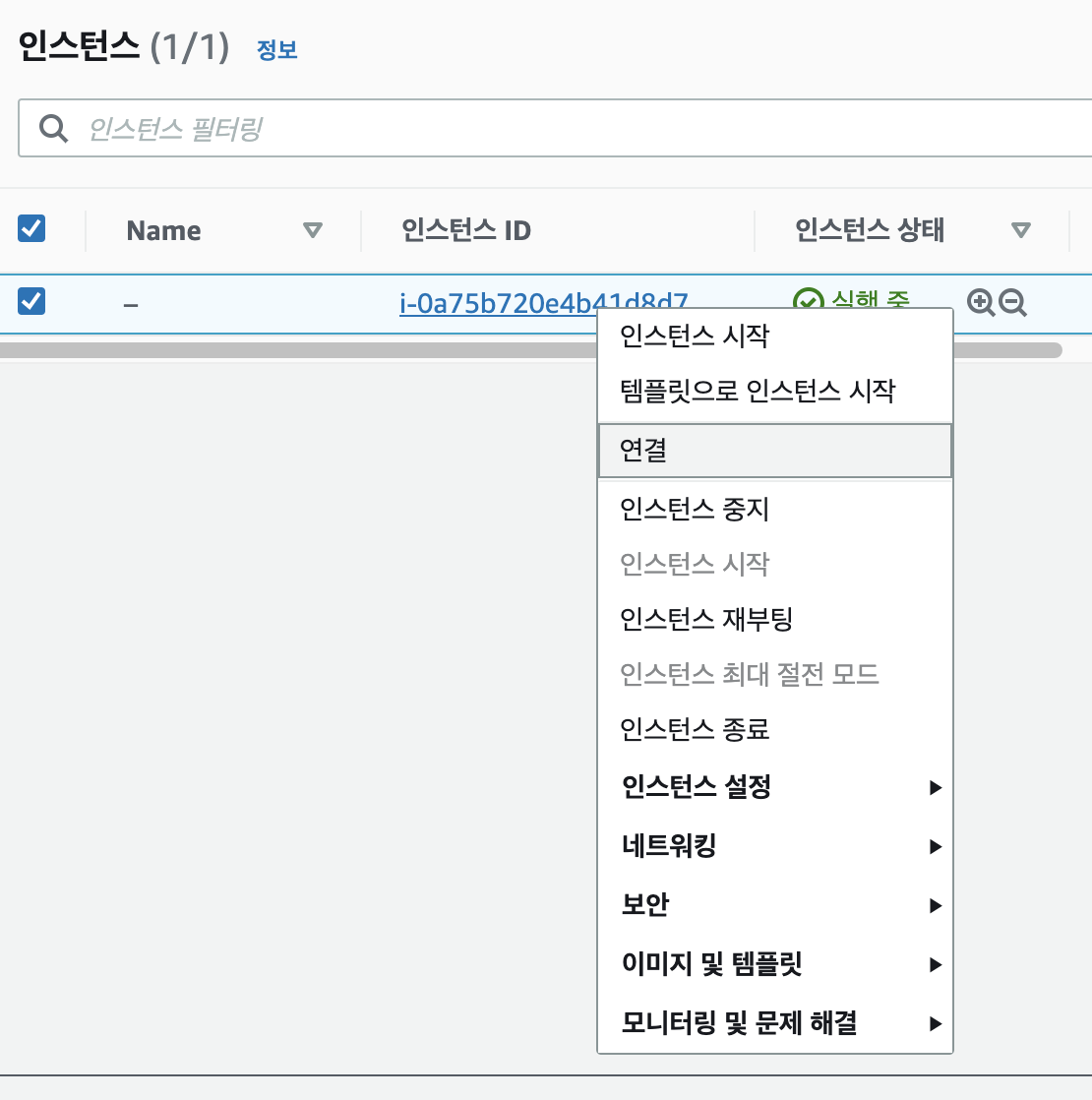
AWS가이드 보는 방법! 인스턴스에서 마우스 우클릭 후 “연결” 클릭하면 나온다.
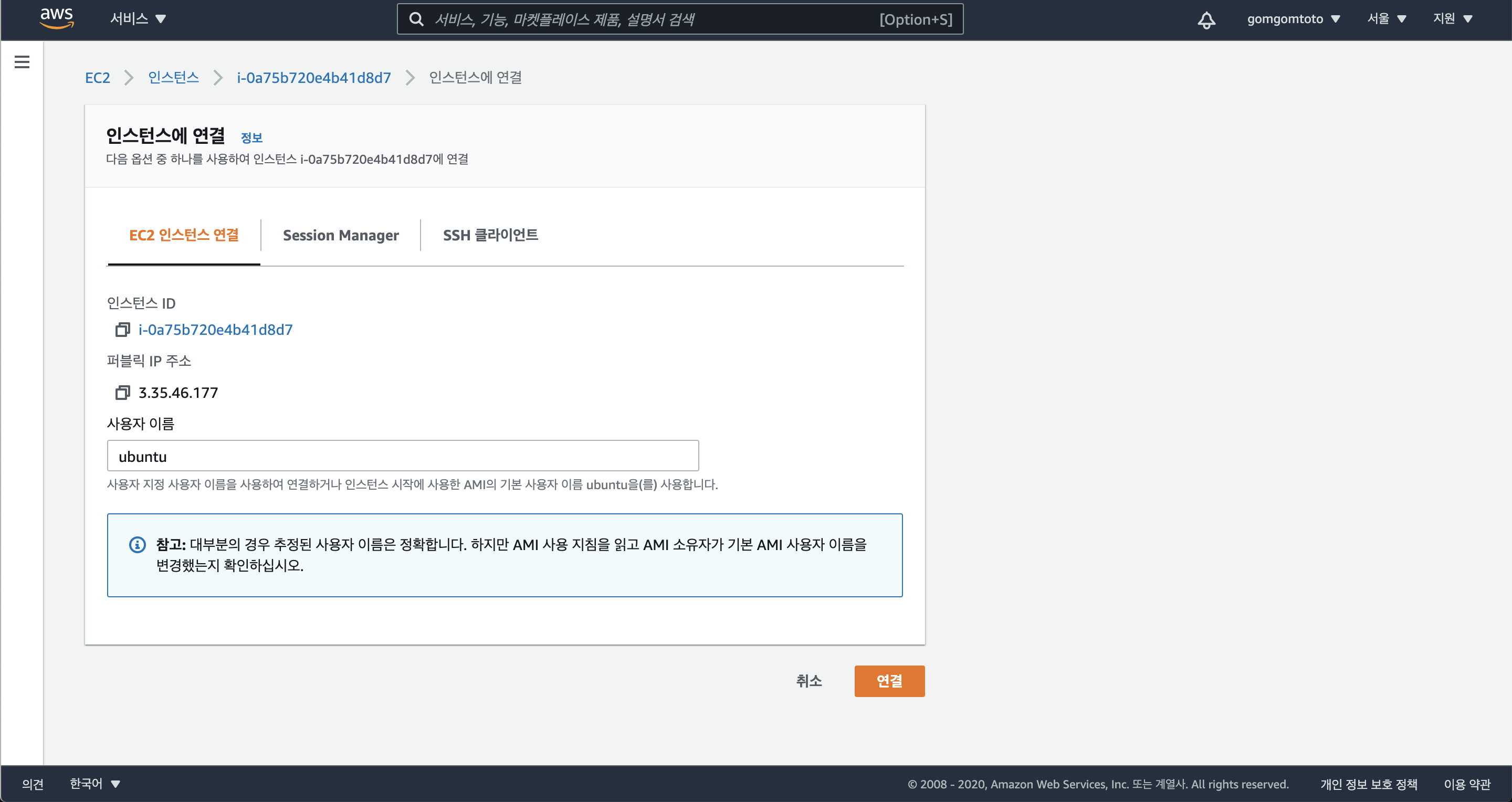
이렇게!
Mac OS 또는 Linux는 자체 터미널로 바로 수행 가능하다.
Windows는 OpenSSH 클라이언트 설치 후 CMD 또는 PowerShell에서 진행 가능하다.
yeochaelin@yeochaecBookPro week4_AWS % ls
kdt.pem
yeochaelin@yeochaecBookPro week4_AWS % chmod 400 yeochaelin@yeochaecBookPro week4_AWS % ls-al
total 8
drwxr-xr-x 3 yeochaelin staff 96 12 21 23:43 .
drwxr-xr-x 11 yeochaelin staff 352 12 21 23:43 ..
-r--------@ 1 yeochaelin staff 1700 12 21 23:16 kdt.pem
yeochaelin@yeochaecBookPro week4_AWS % ssh -i "kdt.pem" ubuntu@ec2-3-35-46-177.ap-northeast-2.compute.amazonaws.com
오래 걸리니까.. 이상한거 아니니까.. 나처럼 열받는다고 ctrl+c로 취소하고 다시하고 반복하지 말기.. 차분히 기다리면 된다…!ㅠㅠ
ubuntu@ip-172-31-44-102:~$ conda activate pytorch_p36
시간이 엄청 걸린다..
>>> import torch
>>> torch.__version__
1.4버전의 torch가 깔린 것을 알 수 있다.
이제 아마존 인스턴스를 사용할 수 있는 상태가 되었다.
원격 접속 및 개발을 위한 VS Code 플러그인 설치
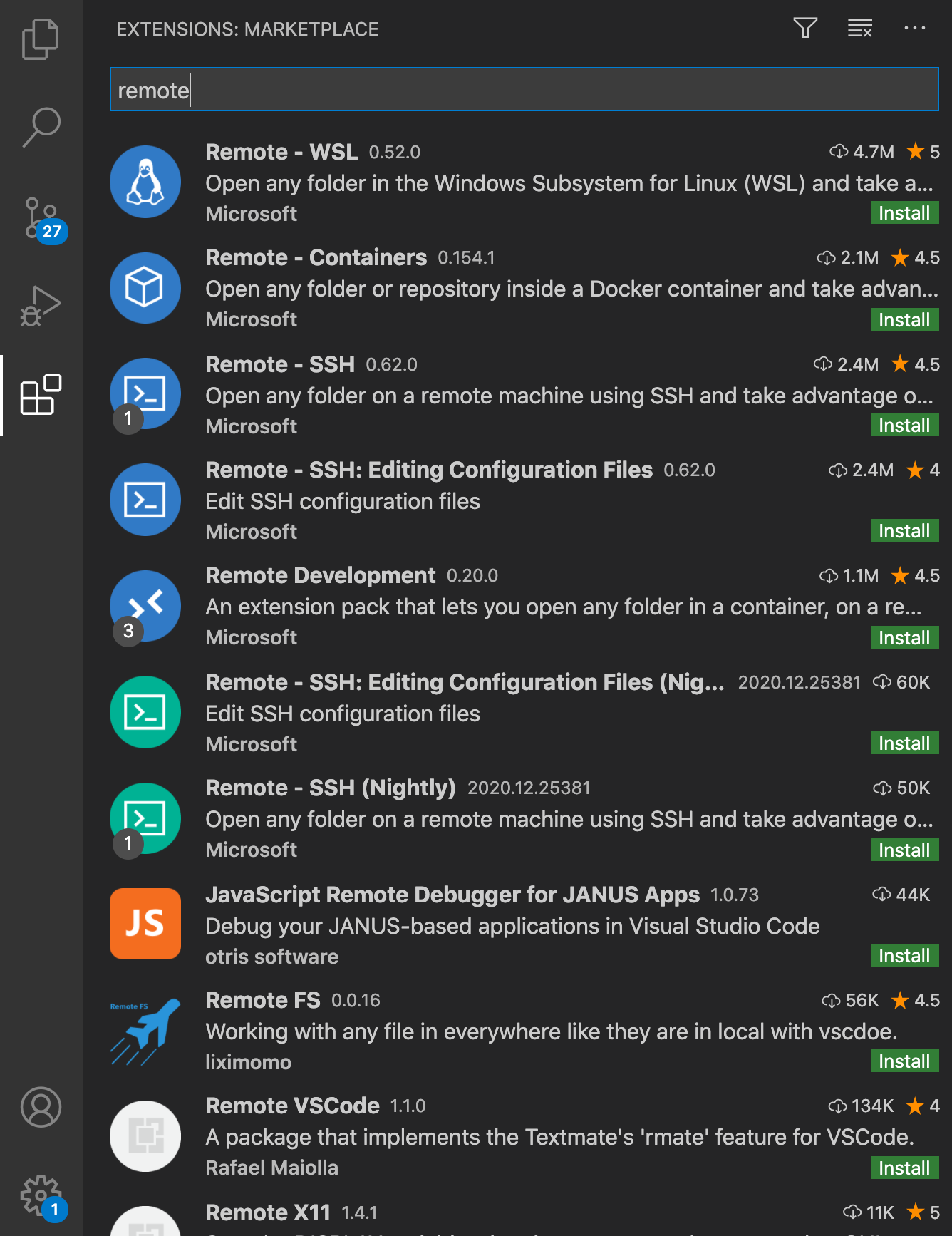
VS Code에서 extension > remote를 검색한다.
이중에서 Remote - SSH를 선택한다.
install을 눌러 설치한다.
설치가 끝나면 Remote Development를 설치한다.
인스턴스에 접속
- Remote-SSH: Connection to Host 선택
- ssh-i “kdt.pem” ubuntu@public-ip-address 입력
- Select SSH configuration file
VS Code 왼쪽 하단에 있는 초록색 >< 버튼을 클릭한다.
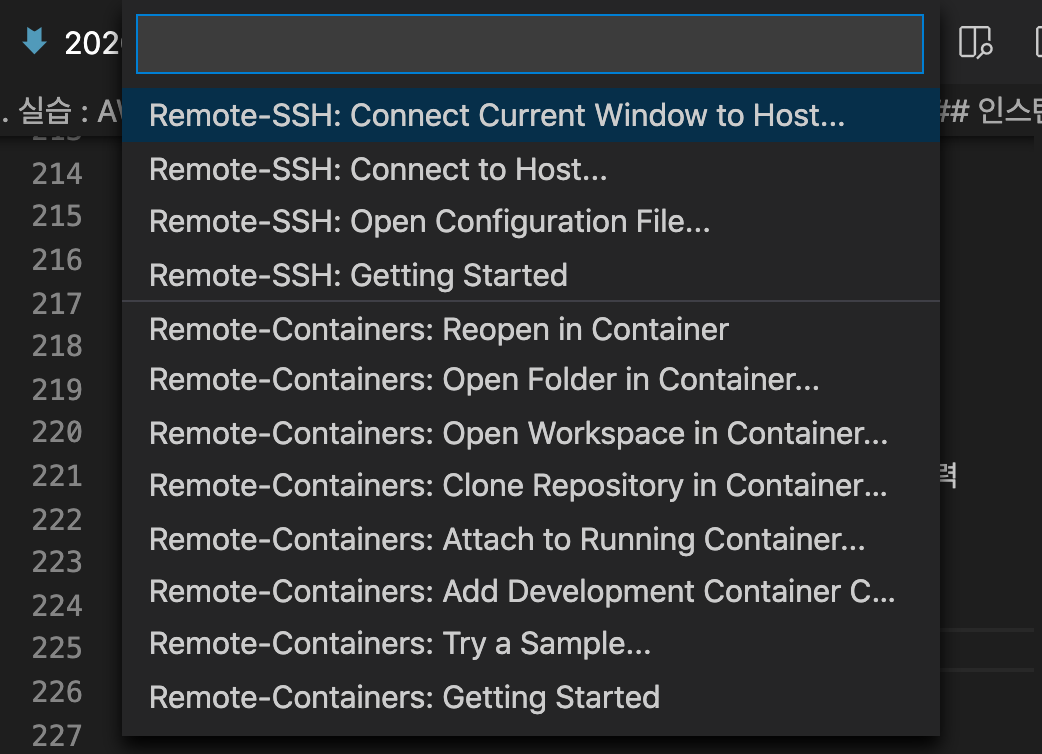
맨 위의 Remote-SSH: Connect Current Window to Host…를 클릭한다.
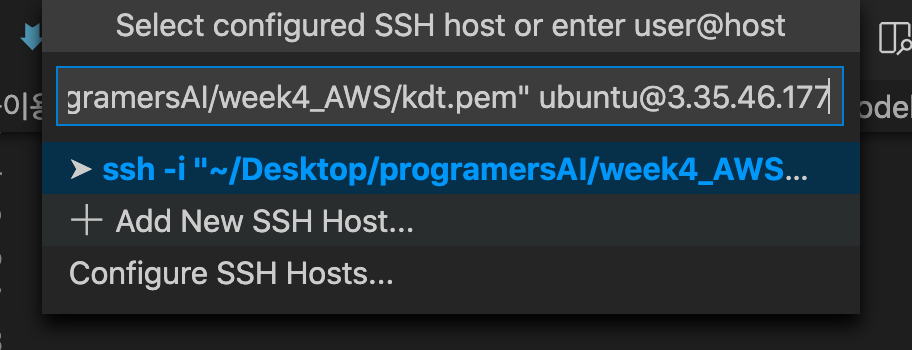
ssh -i “~/Desktop/programersAI/week4_AWS/kdt.pem” ubuntu@3.35.46.177를 입력하고 +Add New SSH Host 클릭!
안된다면 ssh -i “kdt.pem” ubuntu@3.35.46.177로 입력!!

동일하게 입력해준 후 목록에서 맨 상단에 뜨는거 클릭하고 connect 눌러주면 된다.
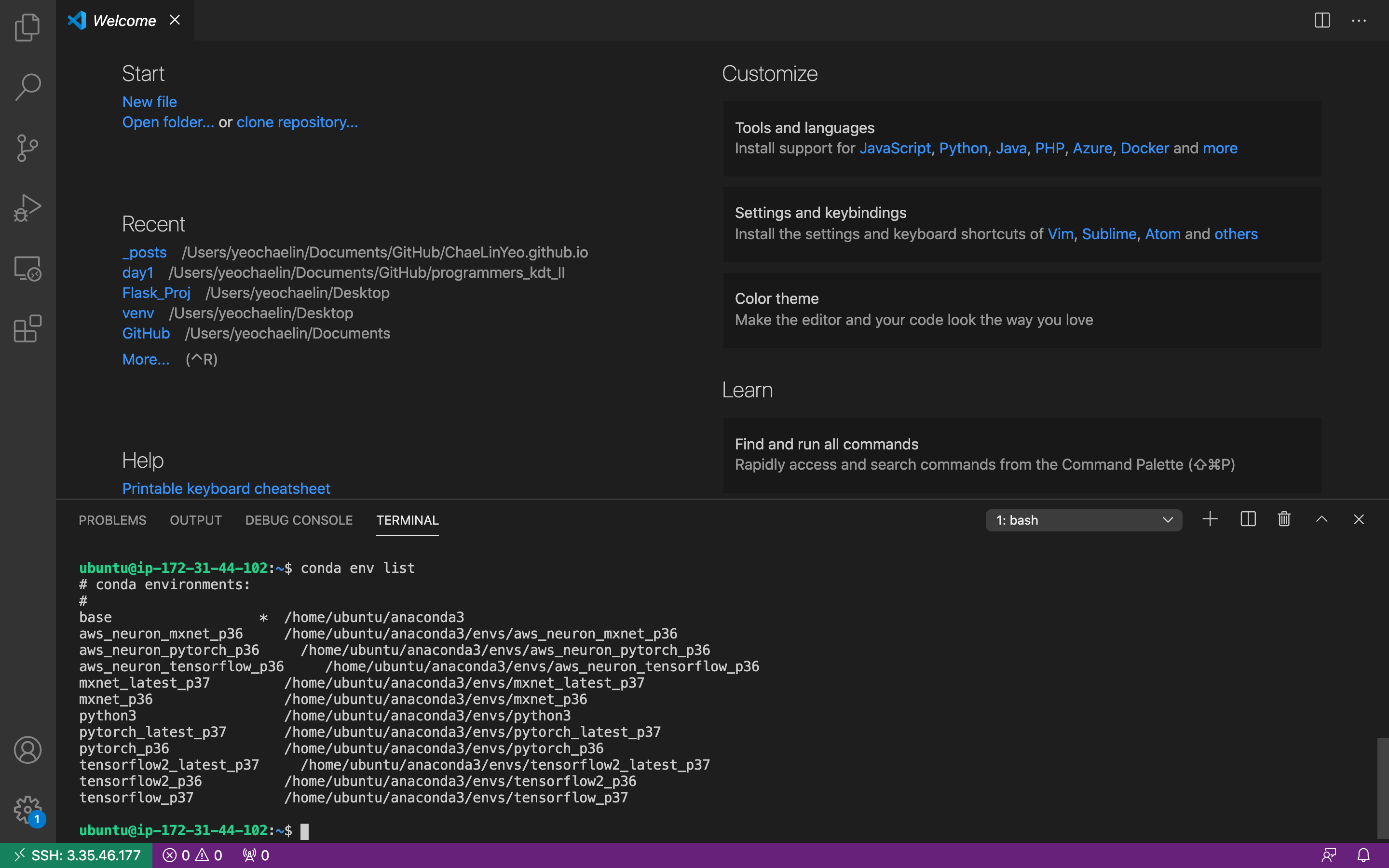
터미널에서conda env list로 세팅되어 있는 가상환경 확인해주면 끝!
3. API to serve ML model
Architecture of API to serve ML model
AWS EC2와 Python Flask 기반 모델 학습 및 추론을 요청/응답하는 API 서버 개발
우리가 만들고자 하는 API에 대한 아키텍처는 다음가 같다.
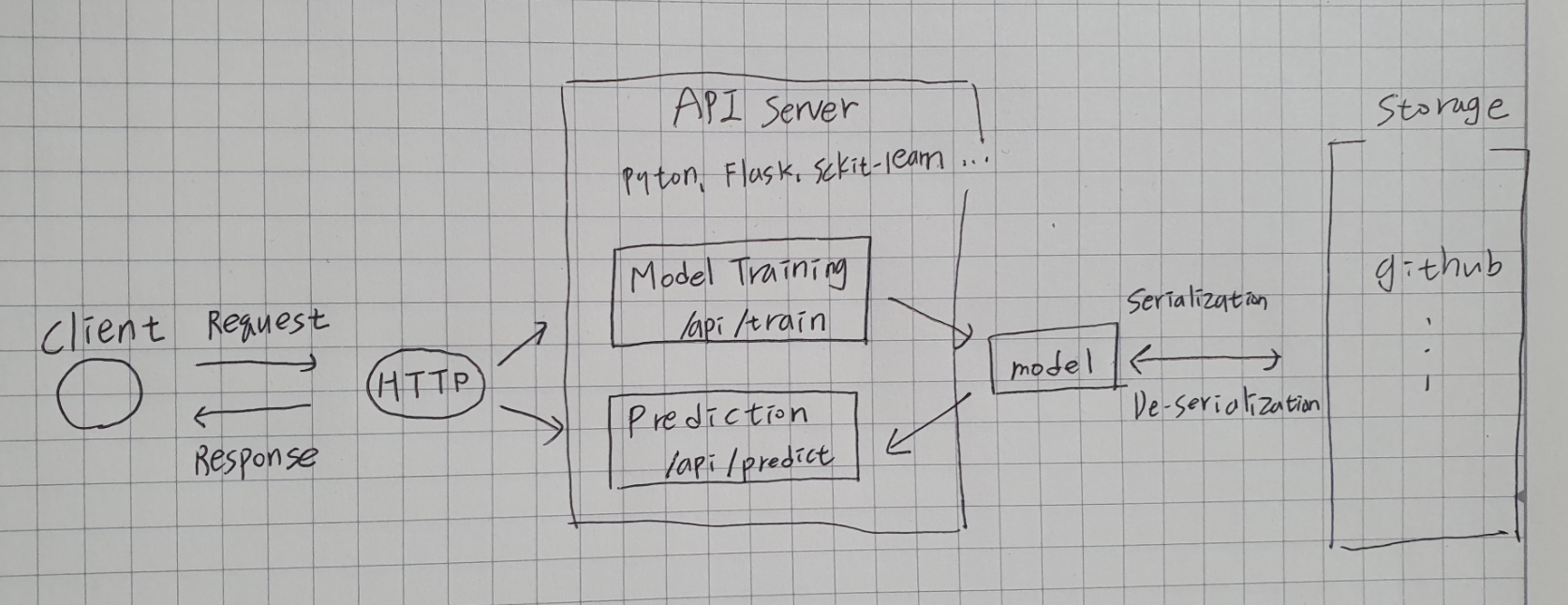
아마존 EC2 컴퓨팅 위에서 API 서버를 만드는 것이 목표이다. API 서버는 파이썬 기반의 flask, 사이킷런, 파이토치같은 머신러닝/딥러닝 프레임웤을 사용할 예정이다.
클라이언트로부터 프로토콜로 요청하면, 모델학습 또는 학습된 모델로부터 예측을 하는 API를 만드는 것이 목표이다.
이 모델은 학습을 통해서 내부 EBS 스토리지에 저장되거나, 외부의 깃헙 저장소 등에 저장될 수 있다.
Interface
사용자는 기계와 소프트웨어를 제어하기 위해 인터페이스를 정해진 매뉴얼에 따라 활용하여 원하는 경험을 획득
컴퓨터의 마우스, 키보드와 같이 입력을 위한 인터페이스와 모니터나 프린터와 같이 정보를 받는 출력을 위한 인터페이스가 있음.
인터페이스는 상호 합의된 메뉴얼에 따라 적절한 입력을 받아 기대되는 출력을 제공할 수 있어야 함
API란?
Application Programming Interface의 약자로 기계와 기계, 소프트웨어와 소프트웨어 간의 커뮤니케이션을 위한 인터페이스를 의미
노드와 노드 간 데이터를 주고 받기 위한 인터페이스로, 사전에 정해진 정의에 따라 입력이 들어왔을 때 적절한 출력을 전달해야 함
RESTful API for ML/DL model inference
REST 아키텍처를 따르는 API로 HTTP URI를 통해 자원을 명시하고 HTTP Method를 통해 필요한 연산을 요청하고 반환하는 API를 지칭
RESTful API는 데이터나 정보의 교환/요청 등을 위한 인터페이스를 REST 아키텍처를 따라 구현한 API
일반적으로 데이터 값을 담아 요청하고 모델이 추론한 결과에 대한 return을 json 형태로 보통 반환하도록 설계
RESTful API는 요청 메시지만 봐도 어떤 내용으로 되어있는지 알 수 있도록 표현됨
–>
[POST]
192.12.0.8.22/detect/
<–
{
id:a43cdf4azleiu,
return:abnormal
}
Practical process of machine learning
문제정의, 데이터준비, 모델 학습 및 검증, 모델 배포, 모니터링 등의 과정을 통해 실제 서비스에 기계학습 모델을 적용
- Define Problems
- Large Raw Data
- Define problems –>
- Prepare Data, Build and Train Model
- Model Learning Lifecycle : Data -> Build&Train -> Test/Evaluate -> 반복… –>
- Trained Model File –>
- Deploy Model, Monitor/Scale in app
- Run/Predict
- Web
- Bots
- Apps
- others…
- Monitor Performance
–> Retrain
우리가 진행해볼 실습은 이 프로세스 중에서도 굵은 글씨로 표시된 Trained Model File과 Run/Predict이다.
저장된 모델 파일을 불러와서 Predict를 해주는 API서버를 만드는 것이 목표이다.
- Run/Predict
Model Serving
학습된 모델을 REST API 방식으로 배포하기 위해서 학습된 모델의 Serialization과 웹 프레임워크를 통해 배포 준비 필요
모델을 서빙할 때는 학습 시의 데이터 분포나 처리 방법과의 연속성 유지 필요
모델을 배포하는 환경에 따라 다양한 Serving Framework를 고려하여 활용
- Model Training
- Data preprocessing
- Model fitting
- Evaluation –>
- Serializing Model
- Save trained model –>
- Serving Model
- Load trained model
- Define inference(추론을 위한 코드를 짠다)
- Deployment(웹 프레임워크를 통해)
이 모든 과정은 연속성이 유지되어야 한다.
만약 앞서 데이터를 처리하는 방식, 모델 분포 등이 다르다면 모델 성능의 저하가 오거나 동작이 제대로 되지 않을 수 있다.
Serialization & De-serialization
학습한 모델의 재사용 및 배포를 위해서 저장하고 불러오는 것
Serialization을 통해 ML/DL model object를 disk에 write하여 어디든 전송하고 불러올 수 있는 형태로 변환(파이썬 오브젝트로 저장된 것을 디스크에 쓰는 것을 Serialization이라고 함. 어디든 전송하고 저장할 수 있는 형태가 됨!)
De-Serialization을 통해 Python 혹은 다른 환경에서 model을 불러와 추론/학습에 사용
모델을 배포하는 환경을 고려해 환경에 맞는 올바른 방법으로 Serialization을 해야 De-serialization이 가능.
Skeleton of handler to serve model
모델을 전처리하고, 사람이 이해할 수 있도록 후처리해주는 작업이 필요하다.
feature는 숫자의 조합으로 이루어져 있는데, 그 결과를 보정하고 반환하는 후처리 작업을 해줘야하는데 이 일련의 과정을 핸들러를 통해 할 수 있다.
핸들러 없이 하드코딩으로 API코딩을 할 수는 있지만 유지 관리 차원에서라도 핸들러 개발하는게 필요!
class ModelHandler(BaseHandler):
def __init__(self):
pass
def initialize(self, **kwargs):
pass
def preprocess(self, data):
pass
def inference(self, data):
pass
def postprocess(self, data):
pass
def handle(self, data):
pass
Model serving을 위한 다양한 Frameworks
딥러닝 모델의 안정적인 serving을 위해 TensorFlow serving이나 TorchServe, TensorRT같은 프레임워크를 사용하는 것이 일반적
실무에서는 보통 텐서플로 서빙이나 토치서빙과 같은 전문 서빙툴을 이용해 모델을 서빙(내부 서빙)하고, 외부와의 통신을 위해서는 플라스크나 기타 프레임워크를 쓴다.
Flask와 같은 웹프레임워크는 클라이언트로부터의 요청을 처리하기 위해 주로 사용
별도의 모델 추론을 위한 AP 서버를 운용하여 내부 혹은 외부 통신을 통해 예측/추론값 반환
대용량 데이터 배치처리와 딥러닝 모델의 활용이 늘면서 multi mode, multi GPU 환경에서의 안정적인 모델 서빙을 위함
4. 실습 : Serialization & De-serialization
Model Serving
학습된 모델을 REST API 방식으로 배포하기 위해서 학습된 모델의 Serialization과 웹 프레임워크를 통해 배포 준비 필요
모델을 서빙할 때는 학습 시의 데이터 분포나 처리 방법과의 연속성 유지 필요
모델을 배포하는 환경에 따라 다양한 Serving Framework를 고려하여 활용
- Model Training
- Data preprocessing
- Model fitting
- Evaluation –>
- Serializing Model
- Save trained model –>
- Serving Model
- Load trained model
- Define inference(추론을 위한 코드를 짠다)
- Deployment(웹 프레임워크를 통해)
Save trained model과 Load trained model을 실습해보자.
실습 환경 세팅
실습 진행을 위해 실습 코드를 깃헙에서 복제
# 아나콘다 가상환경 실행
ubuntu@ip-172-31-44-102:~$ conda activate pytorch_p36
# template 소스코드 다운로드
(pytorch_p36) ubuntu@ip-172-31-44-102:~$ git clone https://github.com/sackoh/kdt-ai-aws
(pytorch_p36) ubuntu@ip-172-31-44-102:~$ cd ./kdt-ai-aws/
# 필요 라이브러리 설치
(pytorch_p36) ubuntu@ip-172-31-44-102:~/kdt-ai-aws$ pip install -r requirements.txt
머신러닝 모델 학습
실습 진행을 위해 사전 준비한 코드를 실행하여 모델 학습 및 저장
(pytorch_p36) ubuntu@ip-172-31-32-254:~/kdt-ai-aws$ python train_ml.py
22-Dec-20 07:40:49 - Downloaded from https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
22-Dec-20 07:40:51 - Downloaded from https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt
22-Dec-20 07:41:02 - fitting Counter vectorizer
22-Dec-20 07:41:04 - Transform raw text into vector
22-Dec-20 07:41:04 - Trained Naive Bayes model.
22-Dec-20 07:41:05 - ML model accuracy score: 82.17%
22-Dec-20 07:41:11 - Saved vectorizer to `model/ml_vectorizer.pkl`
22-Dec-20 07:41:11 - Saved model to `model/ml_model.pkl`
22-Dec-20 07:41:11 - Elapsed time : 0:00:23.074087
여기까지 하면 model training까지 한 것이다.
De-serialization
저장된 모델을 불러와 특정 입력 값에 대한 예측 수행
- 터미널 환경에서 python 또는 ipython, jupyter notebook 실행
- 아래 예제 코드 테스트하여 de-serialization 확인
# De-serialization
import joblib
model = joblib.load('model/ml_model.pkl')
vectorizer = joblib.load('model/ml_vectorizer.pkl')
# Test loaded model and vectorizer
text = '재미있는 영화입니다.'
model_input = model_input = vectorizer.transform(text)
print(model_input.asformat('array'))
model_output = model.predict_proba(model_input)
model_output = model_output.argmax(axis=1)
id2label = {0: 'negative', 1: 'positive'}
print(f'sentiment : {id2label[model_output[0]]}')
결과는 다음과 같다.
(pytorch_p36) ubuntu@ip-172-31-32-254:~/kdt-ai-aws$ python
Python 3.6.10 |Anaconda, Inc.| (default, Jan 7 2020, 21:14:29)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import joblib
>>> model = joblib.load('model/ml_model.pkl')
>>> model
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
>>> vectorizer = joblib.load('model/ml_vectorizer.pkl')
>>> vectorizer
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=100000, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
>>> text = '재미있는 영화입니다.'
>>> text
'재미있는 영화입니다.'
>>> model_input = model_input = vectorizer.transform(text)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/sklearn/feature_extraction/text.py", line 1265, in transform
"Iterable over raw text documents expected, "
ValueError: Iterable over raw text documents expected, string object received.
>>> model_input = vectorizer.transform([text])
>>> model_input
<1x100000 sparse matrix of type '<class 'numpy.int64'>'
with 2 stored elements in Compressed Sparse Row format>
>>> print(model_input.asformat('array'))
[[0 0 0 ... 0 0 0]]
>>> model_output = model.predict_proba(model_input)
>>> model
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
>>> dir(model)
['__abstractmethods__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_abc_cache', '_abc_negative_cache', '_abc_negative_cache_version', '_abc_registry', '_check_X', '_check_X_y', '_check_alpha', '_count', '_estimator_type', '_get_coef', '_get_intercept', '_get_param_names', '_get_tags', '_init_counters', '_joint_log_likelihood', '_more_tags', '_update_class_log_prior', '_update_feature_log_prob', 'alpha', 'class_count_', 'class_log_prior_', 'class_prior', 'classes_', 'coef_', 'feature_count_', 'feature_log_prob_', 'fit', 'fit_prior', 'get_params', 'intercept_', 'n_features_', 'partial_fit', 'predict', 'predict_log_proba', 'predict_proba', 'score', 'set_params']
>>> model_output
array([[0.02618814, 0.97381186]])
>>> model_output = model_output.argmax(axis=1)
>>> model_output
array([1])
>>> id2label = {0: 'negative', 1: 'positive'}
>>> id2label
{0: 'negative', 1: 'positive'}
>>> print(f'sentiment : {id2label[model_output[0]]}')
sentiment : positive
Serialization과 De-serialization 방법은 동일해야 함
joblib으로 serialization을 하고 pickle로 불러올 수 없음
import pickle
with open('model/ml_model.pkl', 'rb')as r:
model = pickle.load(r)
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
_pickle.UnpicklingError: invalid load key, '\x00'.
언피클링 과정에서 에러가 난다. 시리얼라이징을 할 때 과정이 달라졌기 때문에, 불러올 수 없어서 에러가 난다.
5. 실습 : Inference를 위한 model handler 개발
Model Serving
학습된 모델을 REST API 방식으로 배포하기 위해서 학습된 모델의 Serialization과 웹 프레임워크를 통해 배포 준비 필요
모델을 서빙할 때는 학습 시의 데이터 분포나 처리 방법과의 연속성 유지 필요
모델을 배포하는 환경에 따라 다양한 Serving Framework를 고려하여 활용
- Model Training
- Data preprocessing
- Model fitting
- Evaluation –>
- Serializing Model
- Save trained model –>
- Serving Model
- Load trained model
- Define inference(추론을 위한 코드를 짠다)
- Deployment(웹 프레임워크를 통해)
이제 Define inference(추론을 위한 코드를 짠다)를 실습해보자.
전처리를 어떻게 하고, 입력된 결과를 어떻게 후처리하고, 최종적으로 어떻게 API 형태로 만들 것인지.
앞서 잠깐 보았던 스켈레톤 코드를 자세히 뜯어보자.
class ModelHandler(BaseHandler):
def __init__(self):
pass
def initialize(self, **kwargs):
pass
def preprocess(self, data):
pass
def inference(self, data):
pass
def postprocess(self, data):
pass
def handle(self, data):
pass
Handle
handle()
- 요청 정보를 받아 적절한 응답을 반환
- 정의된 양식으로 데이터가 입력됐는지 확인
- 입력 값에 대한 전처리 및 모델에 입력하기 위한 형태로 변환
- 모델 추론
- 모델 반환값의 후처리 작업
- 결과 반환
def handle(self, data): model_input = self.preprocess(data) # 입력된 데이터를 전처리를 한다 model_output = self.inference(model_input) # 모델을 불러와서 인퍼런스를 통해 아웃풋을 낸다 return self.postprocess(model_output) # 후처리를 통해 결과를 반환한다
Initialization
initialize()
- 데이터 처리나 모델, configuration(구성) 등 초기화
- Configuration 등 초기화
- (Optional) 신경망을 구성하고 초기화
- 사전 학습한 모델이나 전처리기 불러오기(De-serialization) Note
- 모델은 전역변수로 불러와야 한다. 만약 inference를 할 때마다 모델을 불러오도록 한다면 그로 인해 발생하는 시간이나 자원 등의 낭비가 발생한다.
- 일반적으로 요청을 처리하기 전에 모델을 불러 둔다.
def initialize(self, ): # De-serializationing model and loading vectorizer import joblib self.model = joblib.load('model/ml_model.pkl') self.vectorizer = joblib.load('model/ml_vectorizer.pkl')De-serialization과 동일한 과정이다.
Preprocess
preprocess()
- Raw input을 전처리 및 모델 입력 가능형태로 변환
- Raw input 전처리
- 데이터 클린징의 목적과 학습된 모델의 학습 당시 scaling이나 처리 방식과 맞춰주는 것이 필요
- 모델에 입력가능한 형태로 변환
- vectorization, converting to id 등의 작업
def preprocess(self, text): # 텍스트가 들어왔을 때 # cleansing raw text model_input = self._clean_text(text) # 텍스트를 클린징하고 # vectorizing cleaned text model_input = self.vectorizer.transform(model_input) # 클린징한 텍스트를 벡터 형태로 변환한다. return model_input # 반환
Inference
inferenc()
- 입력된 값에 대한 예측/추론
- 각 모델의 predict 방식으로 예측 확률분포 값 반환
프레임웤이나 모델 저장 방식에 따라 predict도 많이 달라진다.
def inference(self, model_input): # 모델 인풋값이 들어왔을 때 # get predictions from model as probabilities model_output = self.model.predict_proba(model_input) # 모델이 결과를 반환할 수 있도록 정의 return model_output
- 각 모델의 predict 방식으로 예측 확률분포 값 반환
프레임웤이나 모델 저장 방식에 따라 predict도 많이 달라진다.
Postprocess
postprocess()
- 모델의 예측값을 response에 맞게 후처리 작업
- 예측된 결과에 대한 후처리 작업(모델의 성능 보정)
- 보통 모델이 반환하는 건 확률분포와 같은 값이기 때문에 response에서 받아야 하는 정보로 처리하는 역할을 많이 함
def postprocess(self, model_output): # 모델의 아웃풋 값이 들어오면 # process predictions to predicted label and output format predicted_probabilities = model_output.max(axis=1) # 결과 중에서 가장 높은 확률값을 뽑고 predicted_ids = model_output.argmax(axis=1) # 뽑아온 확률 값이 어떤 레이블에 해당하는지 뽑아준다. predicted_labels = [self.id2label[id_] for id_ in predicted_ids] # 이렇게 뽑은 값은 0또는 1로 이루어진 값이기 때문에, 레이블 값으로 변환하여 사람이 알아볼 수 있게 한다. return predicted_labels, predicted_probabilities #반환되는 결과는 각 텍스트에 대한 분석 결과를 레이블 형태로 표현하고, 그 레이블 값에 대해서 어느정도 확률값을 가지는지를 표현한다.
Testing ML model handler
from model import MLModelHandler
ml_handler = MLModelHandler() # 전역변수로 핸들러
# 아래에서 API 호출 및 수행
text = ['정말 재미있는 영화입니다.', '정말 재미가 없습니다.']
result = ml_handler.handle(text)
print(result)
터미널에서 python 치고 들어가서 입력하면…
(['positive', 'negative'], array([0.98683823, 0.79660478]))
다음과같이 두 텍스트에 대한 긍정적/부정적 퍼센트를 볼 수 있다!
6. Flask 기반 감성분석 API 개발
네이버 영화리뷰 감성분석 개요
네이버 영화리뷰 데이터로 학습한 ML/DL 모델을 활용해 감성분석 API 개발
나이브베이지안 모델과 딥러닝 모델로 학습한 두 개의 모델을 서빙하며 0은 부정을 1은 긍정을 의미
학습에 사용한 데이터는 박은정님이 공개한 NSMC 데이터
- 클라이언트가 영화 리뷰 텍스트 POST predict 요청 “영화가 재미 없어요”
- Prediction에서 do_fast 요청 정보에 따라 ML 또는 DL 모델로 예측
- 감성분석 결과 반환
API 정의
key:value 형태의 json 포맷으로 요청을 받아 text index 별로 key:value로 결과를 저장한 json 포맷으로 결과 반환
POST 방식으로 predict 요청
do_fast를 true로 할 경우, 빠른 추론 속도가 가능한 머신러닝 모델로 추론하도록 함
false의 경우, 추론 속도는 비교적 느리지만 정확도가 높은 딥러닝 모델로 추론하도록 함
# [POST]/predict
json = {
"text" : ["review1", "review2", ...],
"do_fast" : true or false
}
사전 학습한 딥러닝 모델을 활용하여 머신러닝 모델 handler와 동일한 입력에 대해 동일한 결과를 반환하는 handler 개발
사전 학습한 모델은 Hugging Face에서 제공하는 외부 저장소에서 다운로드 받아 불러옴
import torch
def initialize(self, ):
from transformers import AutoTokenizer, AutoModelForSequenceClassification
self.model_name_or_path = 'sackoh/bert-base-multilingual-cased-nsmc'
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name_or_path)
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name_or_path)
self.model.to('cpu')
def preprocess(self, text):
#preprocess raw text
model_input = self._clean_text(text)
# vectorize cleaned text
model_input = self.tokenizer(text, return_tensors='pt', padding=True)
return model_input
def inference(self, model_input):
with torch.no_grad():
model_output = self.model(**model_input)[0].cpu()
model_output = 1.0/(1.0+torch.exp(-model_output))
model_output = model_output.numpy().astype('float')
return model_output
def postprocess(self, model_output):
# process predictions to predicted label and output format
predicted_probabilities = model_output.max(axis=1)
predicted_ids = model_output.argmax(axis=1)
predicted_labels = [self.id2label[id_] for id_ in predicted_ids]
return predicted_labels, predicted_probabilities
def handle(self, data):
# do above process
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)
이제 유닛테스트 실행!!
python -m unittest -v test_model_handler.py
ModuleNotFoundError: No module named 'transformers'
가 떠서 pip로 설치해줌.
pip install transformers
Killed라고 뜬다;;;
Flask API 개발 & 배포
Model을 전역변수로 불러오고 요청된 텍스트에 대해 예측 결과를 반환하는 코드 입력
app.py를 열어 다음을 입력한다.
ml_handler = MLModelHandler()
dl_handler = DLModelHandler()
if do_fast:
predictions = ml_handler.handle(text)
else:
predictions = dl_handler.handle(text)
Test API on remote
원격에서 서버로 API에 요청하여 테스트 수행
host : EC2 인스턴스 생성 시에 받은 퍼블릭 IP 주소 또는 직접 할당한 탄력적 IP주소
port : EC2 인스턴스 생성 시에 설정했던 port 번호 (ex. 5000)
conda activate pytorch_p36된 상태에서
python app.py
돌아가는동안, 로컬 터미널을 열어 다음을 입력한다.
curl -d '{"text":["영화 오랜만에 봤는데 괜찮은 영화였어", "정말 지루했어"], "use_fast": false}' \
-H "Content-Type: application/json" \
-X POST \
http://3.34.82.97:5000/predict
로컬 터미널에서 python3을 입력후 다음을 테스트해볼 수 있다.
import requests
url = 'http://host:port/predict'
data = {"text":["영화 오랜만에 봤는데 괜찮은 영화였어", "정말 지루했어"], "use_fast": false}
response = requests.post(url, json=data)
print(response.content)
과제 : Train API 추가
ML model 학습요청 API 개발
Serialization 실습에서 실행했던 ‘train_ml.py’ 참조하여 http://host:port/train 으로 모델 학습을 요청하는 API 추가
- 클라이언트가 POST 또는 GET 요청
- Model Training에서 다음 수행
from time import time from train_ml import * start_time = time.now() for mode in ['train', 'test']: download_data(mode) model, vectorizer = train_and_evaluate() serialization(model, vectorizer) response = time.now() - start_time - 학습 수행 시간 반환 : 3.69sec