
[Visual Recognition]GAN, Style Transfer
Visual Recognition: Generative Models
Probability Density function
확률분포함수. PDF. 각 샘플에 대해 나오는 결과들의 분포.
확률변수 X가 취하는 값이 실수 구간 또는 실수 구간의 합으로 주어질 때, 연속확률변수라고 한다. 예를 들어, 임의로 선택한 사람의 키나 어느 지역의 연간 강수량과 같은 측정치는 연속확률변수이다. 연속확률변수의 확률분포는 한 점에서의 확률이 아니라 어느 구간에 속할 확률로 정의하는데, 한 점에서의 상대적 가능성을 나타내는 확률밀도함수를 이용하여 정의한다.
가정: 영상이 2차원 벡터이고, 다음과 같은 PDF를 가진다고 가정. 예를 들어 다음과 같이
- (3,2): 얼굴일 확률이 0.9
- (4,1): 얼굴일 확률이 0.01
실제 영상은 n차원 벡터 -> n개의 축을 가진 PDF로부터 생성된 샘플이라고 볼 수 있다.
영상을 만들어내는 PDF를 알고 있으면 영상을 생성할 수 있음. PDF의 값이 큰 샘플을 생성하면 됨. -> 문제는, 이 PDF를 구하는 것이 불가능함.
그래서 나온 것이 GAN!
GAN
Generative Adversarial Network(적대적으로 생성하는 네트워크)
PDF를 구하려는 시도가 아닌 다른 시도를 해보자는 것에서 나온 GAN!
초기의 GAN은 Generator(생성자)와 Discriminator(판별자)로 이루어졌다. 이 둘이 서로 경쟁하면서 성능을 올리는 방식이었다.
- Generator: 정교하게 위조화폐를 생성한다.
- Discriminator: 위조화폐인지 아닌지 판별한다.
- 노이즈 -> Generator -> 가짜 생성 -> Discriminator에게 진짜를 줌 -> 가짜 or 진짜 판별 후 Generator에게 피드백
GAN에서는 Generator가 어떤 내용을 만들어내느냐가 진짜 데이터에 따라 달라진다. 고양이는 워낙 포즈가 다양해서 진짜같은 고양이를 만들어내기가 사람에 비해 어렵다.
GAN은 노이즈로부터 어떠한 새로운 내용을 만들어내는 함수와 같다.
분포 매핑함수로서의 GAN
GAN은 노이즈로부터 어떠한 새로운 내용을 만들어내는 함수와 같다. 가우시안 노이즈가 인풋으로 주어지면 (가우시안 분포로부터 생성한 노이즈) generative network를 통과해서 사람 얼굴을 만들어서 출력해준다.
Discriminator의 역할
진짜 얼굴 사진이 들어오면 큰값(1), 가짜 얼굴 사진이 들어오면 작은값(0)을 내보내는 함수 역할을 한다.
Discriminator은 큰값이 나온것을 만들어내고, 작은값이 나온것은 만들지 말라고 Generator에게 피드백을 한다.
Generator는 이 피드백으로 업데이트를 한다.
Discriminator Network
초기의 Discriminator의 네트워크는 입력으로 이미지가 들어가면 4개의 컨볼루션을 지난다. 각 컨볼루션마다 파라미터들이 나온다. 컨볼루션을 지날 때마다 작아져서 나중에 1 or 0(진짜/가짜) 판별 값으로 나온다.
파라미터들: 컨볼루션에 쓰이는 필터의 weight 값들.
Generator Network
Generator도 컨볼루션 뉴럴 네트워크이다. 입력으로 노이즈가 들어가면 4개의 컨볼루션을 지난다. 컨볼루션을 지날 때마다 커져서 output으로 컬러영상이 된다.
Strided Convolution
컨볼루션할때 사이즈가 커지는 것은 Fractionally-strided convolution을 이용하는 것이다.
Cost Function
필터의 파라미터를 찾으려면 cost function을 최소화해야 한다.
초기의 논문의 비용함수는 다음과 같다.
$V(D) = log D(X) + log(1 - D(\hat X))$
- $X$: Real image
- $\hat X$: False image
V(D)라는 함수는 이 값을 크게하는 D를 찾고자 한다. (로스가 커지기를 원한다.) 여기에 -를 붙이면 로스를 최소화하는 함수가 된다.
가짜 영상을 $\hat x = G(Z)$라고 하자.
$V(D, G) = log D(X) + log(1 - D(G(Z)))$
여기까지는 하나의 영상에 대한 식이다. 이제 여러개의 영상에 대해 식을 표현해보면…
$J^{(D)} = \sum_X log D(X) + \sum_Z (1 - D(G(Z)))$
이 sumation에 대한 expected value, 평균값을 구하면 다음의 식이 된다. 하지만 이 식은 개념적인 것이고, 사실상 계산이 불가능하다.(전세계 모든 사람들의 진짜 얼굴 평균…)
$J^{(D)} = E[log D(X)] + E[log (1-D(g(Z)))]$
최적화 방법
Cost function:
$V(D, G) = E_{X ~ p_{data}} [log D(X)] + E_{Z ~ p_z(Z)} [log (1 - D(G(Z))])$
Problem:
$min_G max_D V(D, G) = E_{X ~ p_{data}} [log D(X)] + E_{Z ~ p_z(Z)} [log (1 - D(G(Z))])$
위와같은 Problem을 해결하는 방식으로 하면 최적화가 된다!
max D를 위해서는 Gradient Ascent(Gradient Descent의 반대)를 수행하면 된다.
max G를 위해서는 Gradient Descent(Gradient Ascent의 반대)를 수행하면 된다.
Walking in the latent space
latent는 노이즈 Z를 말한다.
Z자체는 노이즈이지만, G라는 함수에 대한 매핑이 이루어지면서 의미있는 결과가 나온다.(5에서 9로 변한다던지)
latent space가, 각각의 노이즈 하나하나가 output의 이미지 하나하나를 책임지는 의미를 갖게 된다. 의미를 갖게 되는 것은 G에 의해 Z에게 의미를 부여하기 때문이다.
Fixed Loss의 단점
고정된 loss를 갖고 있으면 성능이 안좋아진다. 고정된 결과를 내야하기 때문에 성능을 저하시킨다. 서로 다른 영상에 대해 서로 다르게 배우기 때문에, 새로운 영상이 들어오면 각자 다르게 배운것의 평균을 내서 output을 내기 때문.
Universal loss
Generated images(fake), Real photos -> Generative Adversarial Network(Generated vs Real), 즉 classifier
Generator가 이제 인풋으로 노이즈가 아닌 흑백/저해상도 영상을 받아서 아웃풋으로 연산처리한 결과를 반환한다. 단지 아웃풋에 로스를 하나 더해주어 가능한 한 진짜와 구분이 안되는 것이 되도록 하는 것이다.
구조
- X -> G(Generator) -> G(X) -> D(Discriminator) -> real or fake?
- G tries to synthesize fake images that fool D
- D tries to identify the fakes
- X -> G -> G(X) -> Loss Function D
- G’s perspective: D is a loss function
- Rather than being hand-designed, it is learned
디자인된 로스가 아닌, 진짜로부터 학습이 되는 고정적이지 않는 로스이다.
PatchGAN
PatchGAN을 사용: Patch단위로 Discriminate
Discriminator의 출력크기에 따른 생성이미지 품질: 출력 크기가 작더라도 충분히 Discriminator를 속일 수 있다.(화질이 안좋네..대충 실제 영상같은데? 하고 진짜라고 판단해버림) 그래서 굳이 출력크기를 크게 만들지 않는다.
출력크기를 크게 하면 그만큼 디테일을 정교하게 만들어내야 한다.
Pix2Pix Loss 함수
$G^* = arg min_G max_D \pounds_{cGAN}(G, D) + \lambda \pounds_{L1}(G)$
- 만들어지는 것(G)과 진짜(y)의 차이를 작게 만든다. 이 점이 이전의 fixed loss와 달라진 점!
Pix2Pix structure
x(흐릿한 영상) + z(노이즈) -> G(x, G(x,z)) -> G(x) -> D -> fake
x(흐릿한 영상). y(진짜 영상) -> D(x,y) -> real
Pix2Pix 결과
- Labels to Street Scene
- Labels to Facade
- Black&White to Color
- Edges to Photo
- DAy to Night
- Aerial to Map
Conditional GAN
Pix2Pix도 Conditional GAN에 포함된다고 볼 수 있음.
Original GAN에 어떤 condition을 가하는 방법은 간단하다. Generator와 Discriminator에 특정 condition을 나타내는 정보 y를 가해주면 된다.
Stack GAN
Text description -> StackGAN Stage-1(64 * 64 images) -> StackGAN Stage-2(256 * 256 images)
텍스트를 이해해서 이미지를 생성한다.
Conditional + Stack GAN
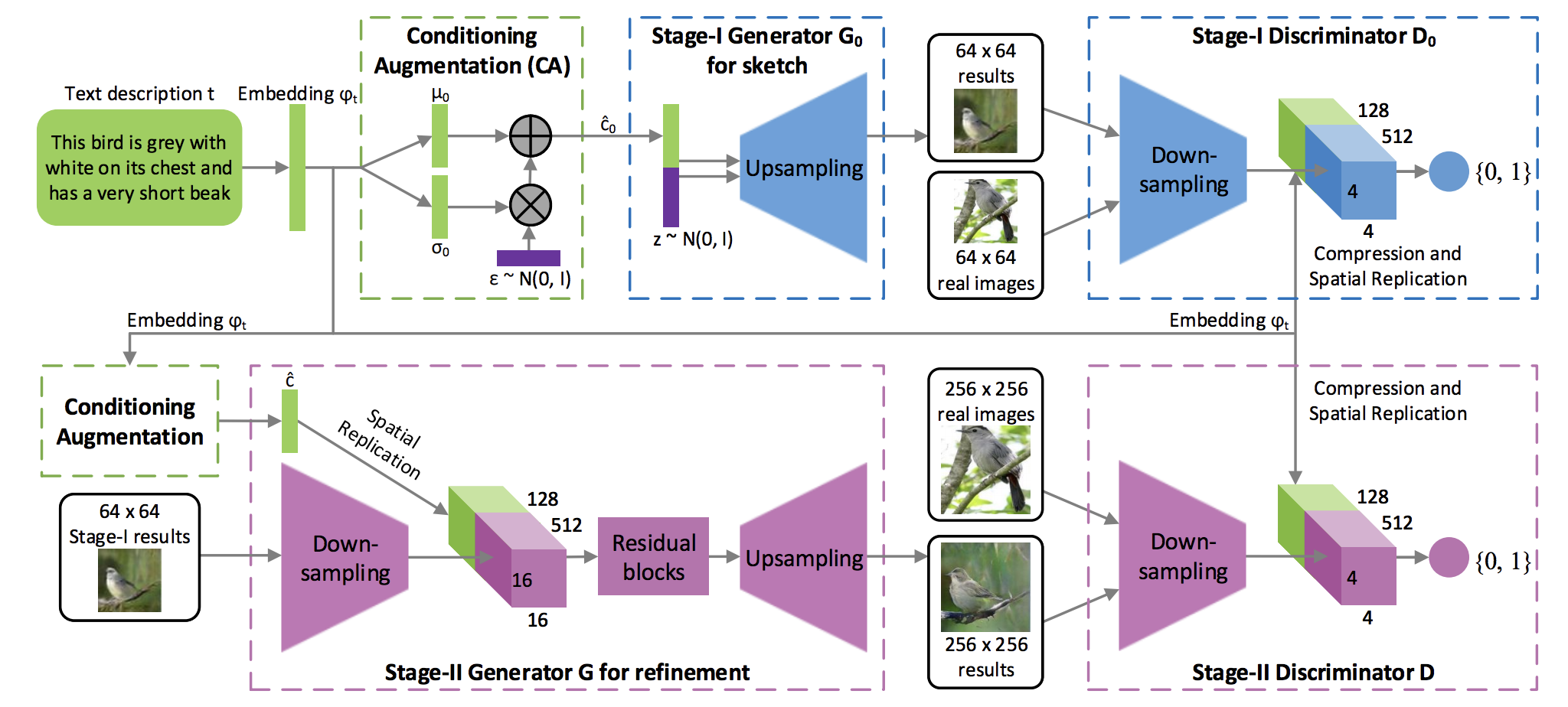
- 출처: https://machinelearningmastery.com/tour-of-generative-adversarial-network-models/
노이즈와 텍스트(임베딩으로 바꾼 벡터를 제너레이터에 넣은것)을 넣어 이미지를 만들 수 있다.
한번에 만들기 힘들기 때문에 Progressive GAN이 나왔다.
두 스텝으로 나눠서 진행된다.
Progressive GAN
style GAN에서도 이 Progressive GAN의 개념을 차용해서 쓴다.
이미지를 시각화하여 네트워크에 층을 추가하여 점진적으로 해상도를 높이는 방식. 점진적으로 구조(특징)을 파악하면서 다음 계층에서 특징이 점점 세부화 되어 모든 스케일에 특징이 담겨짐 -> 저차원에서부터 시작하면 미리 고차원의 구조를 알 수 있다.