
[Visual Recognition] MaskRCNN, GAN(Generative Adversarial Networks)
Visual Recognition: Semantic Segmentation
Semantic Segmentation & Instance Segmentation
Object Detection: x,y좌표로 박스체킹하여 4개의 점으로 오브젝트 영역을 구분한다.
Semantic Segmentation: 의미론적으로 분할하였다는 뜻. 픽셀단위로 오브젝트를 구분한다. 동일한 오브젝트가 여러개 있으면 여러개의 오브젝트를 하나로 구분한다.
Instance Segmentation: 동일한 오브젝트가 여러개 있으면 개별적인 오브젝트도 픽셀 단위로 구분한다.
Semantic Segmentation의 응용
- 자율주행 시 정교하게 위치와 크기를 디텍트할 수 있음.
- 이미지 누끼 따기/인물사진(사람이 아닌 배경 흐리게 만들기)
- x-ray 흑백 의료영상에서 장기 위치 세그멘테이션하여 칼라 입히기
Semantic Labels
- 영상의 픽셀만큼 레이블이 주어져야 한다.
- 영상의 픽셀마다 클래스별로 다른 레이블 값을 가져야 한다.
- 하나의 채널(맵)마다 하나의 클래스에 대해서만 0(클래스에 해당하지 않는 부분)/1(클래스에 해당하는 부분)으로 이루어진다.
- 픽셀 단위 손실은 가능한 모든 클래스에 대해 합산된 로그 손실로 계산된다. 이 스코어는 모든 픽셀에 대해 반복되고 평균화된다.
1. Semantic Segmentation
Input($3 * H * W$) -> Convolutions($D * H * W$): 여러개의 컨볼루션 수행 -> Scores($C * H * W$): argmax 수행 -> Predictions($H * W$)
- 영상 사이즈 만큼의 컨볼루션을 수행해야 하므로 연산이 오래걸리고 채널이 너무 길어진다!! 따라서 보통은 다음의 구조로 만든다. Input($3 * H * W$) -> High-res -> Med-res: 풀링 수행 -> Low-res: 풀링 수행 -> Med-res: 크기 키움 -> High-res: 크기 키움 -> Predictions($H * W$)
- 같은 크기로 계속 컨볼루션 하는게 아니라, 한번씩 풀링을 해서 영상을 줄여가며 컨볼루션을 수행하다가 다시 키워 마지막에 다시 원래 영상 사이즈와 같아지게 한다.
- 풀링으로 작아지는 부분을 encoder, 다시 원본사이즈로 커지는 부분을 decoder라고 하여 이런 형태의 모델을 encoder-decoder network라고 한다.
FCN(Fully Convolutional Network)
Semantic Segmentation을 맨 처음 제안했던 논문이다.
이 논문은 Semantic Segmentation을 했다는 점, 그리고 fully convolution한 네트워크를 제안한 점에서 의미가 크다.
- fully convolution: 이전까지는 어떤 레이어까지는 컨볼루션을 쓰다가 마자막에 flatten 후 fully connect를 썼다. fully convolution 네크워크에서는 컨볼루션만 쓴다. 따라서 입력 영상 사이즈에 구애를 받지 않는다. 입력 영상 사이즈를 고정된 사이즈로 할 필요가 없다!
- 풀링으로 컨볼루션 사이즈를 계속 줄이다가 출력 전에 다시 원본 영상 사이즈로 키우는 작업을 하는데, 이 기술을 Upsampling이라고 한다. 그럼 원본 영상에 대응되는 원본크기의 segmentation map이 출력된다.
Bilinear Interpolation(보간법)
2개의 숫자가 있으면 그 사이를 채우고 싶을 때 그 값을 경향적으로 정해주는 방법.
2개의 숫자 A, B가 있으면 그 사이 값은 다음과 같이 계산된다.
- $A {D2 \above 1pt D1 + D2} + B {D1 \above 1pt D1 + D2}$
2-D Bilinear Interpolation(보간법)
4개의 숫자 A, B, C, D가 있으면 그 사이 값은 다음과 같이 계산된다.
- $X = (A {H2 \above 1pt H1 + H2} + B {H1 \above 1pt H1 + H2}) {W2 \above 1pt W1 + W2} + (D {H2 \above 1pt H1 + H2} + C {H1 \above 1pt H1 + H2}) {W1 \above 1pt W1 + W2}$
3 by 3 맵을 9 by 9 맵으로 키워야 한다면, 커지면서 생기는 빈칸들의 값을 위의 식을 통해 보간한다.
해상도는 증가하지 않고, 크기만 커진 것.
단일 scale의 약점
위처럼 단일한 인코더-디코더를 수행할 경우(하나의 스케일만을 사용하여 세그멘테이션을 하게 되면) 해상도가 낮은 segmentation map이 얻어지므로 정보손실이 일어난다.(세밀한 정보를 잃게 된다.)
따라서 FCN에서는 여러개의 스케일을 사용하는 멀티 스케일을 사용한다.
Multi-scale Prediction
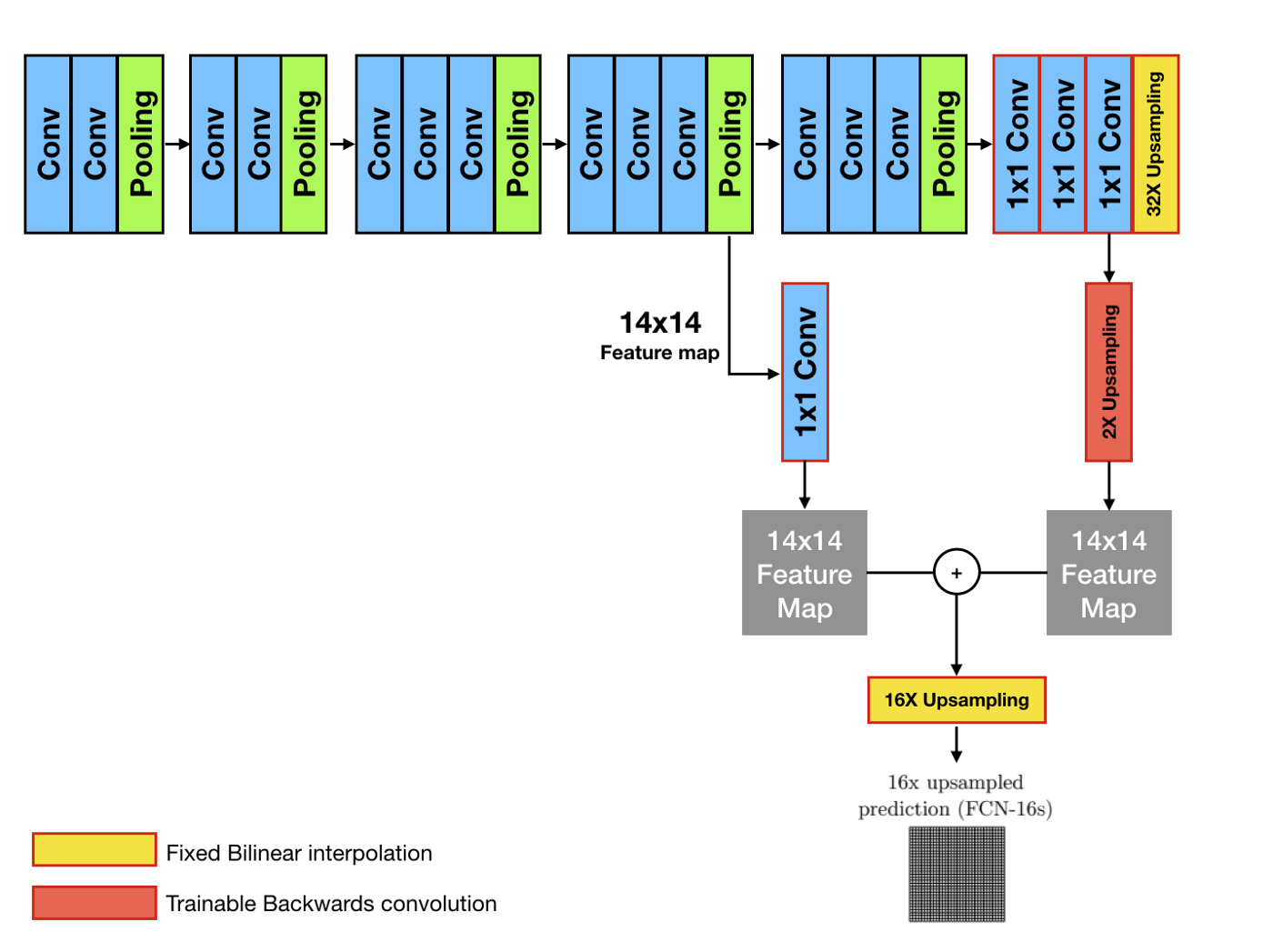
- 출처: https://medium.com/@msmapark2/fcn-논문-리뷰-fully-convolutional-networks-for-semantic-segmentation-81f016d76204
pooling을 하다가 upsampling을 할 때 Bilinear Interpolation을 한다.(그림의 노란색 부분)
마지막 풀링을 하기 전에, 마지막 풀링 직전 단계의 영상 피쳐맵을 갖고와서 1by1 컨볼루션을 하고, 이를 upsampling된 피쳐맵과 합친다. 그러면 풀링에 의해 잃어버린 정보를 회복할 수 있다.
그림에서 빨간색의 upsampling의 경우 학습이 가능한 backword convolution을 사용한다.
Transpose convolution = Stride convolution, backward convolution, deconvolution
영상이 커지면 원래 픽셀이 아닌 부분은 빈칸이 된다.
예를 들어 $2 * 2$를 $4 * 4$로 만들면서 1개의 값으로 9개의 값을 유추한다. Transpose convolution은 컨볼루션 필터 작업으로 채워나가게 된다.
PSPNet(Pyramid Scene Parsing Network)의 구조
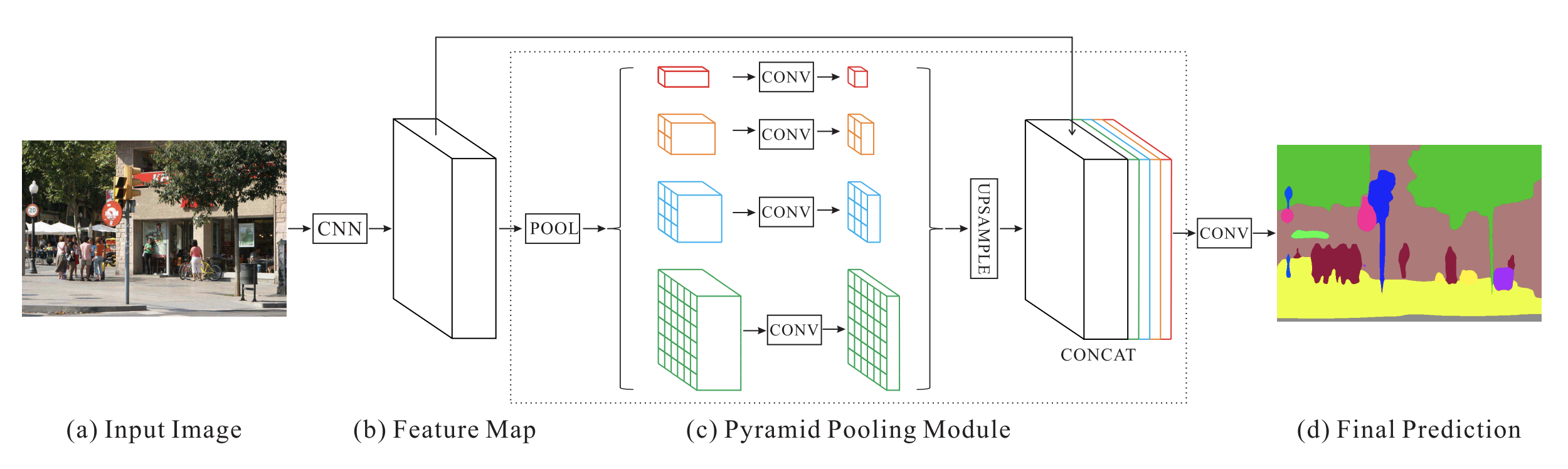
- 출처: https://arxiv.org/abs/1612.01105
풀링을 피라미드 구조로 여러 종류를 한꺼번에 적용함. 그리고 한번에 upsampling하여 쌓는다. concat을 하면 다양한 스케일의 정보가 같이 포함될 수 있다.
성능비교
https://arxiv.org/abs/1612.01105 의 논문에 따르면 FCN보다 PSPNet의 성능이 더 좋다.
UNet
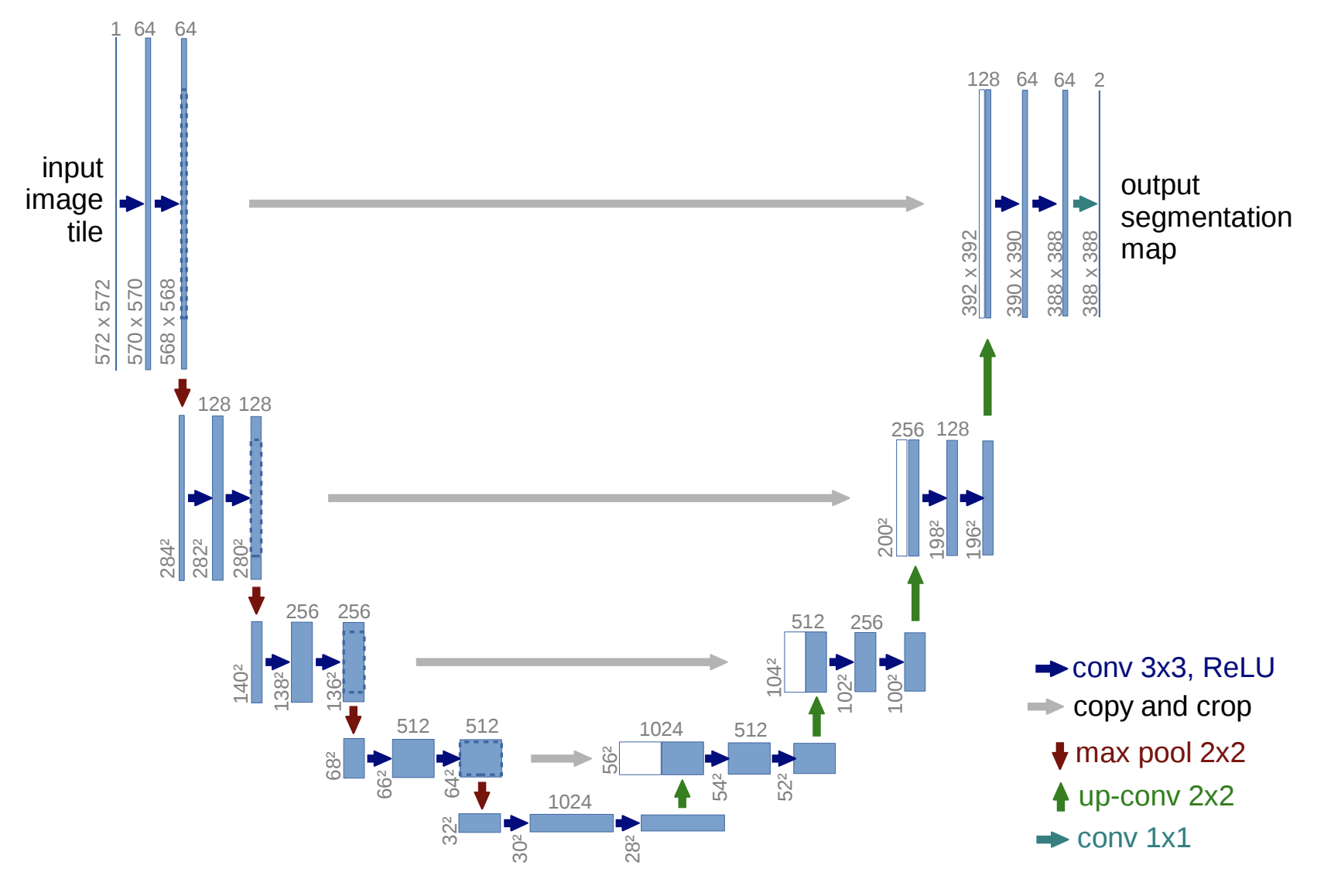
- 출처: https://arxiv.org/abs/1505.04597
단순한 인코더-디코더와 다른 점은, 잃어버리는 정보를 추가해서 더해주는 connection이 있다는 것이다.
개선된 UNet
- Standard U-Net: 기존의 UNet에서 skip connection이 추가되었다.
- dual frame U-Net: 기존의 UNet에서 skip connection이 추가되었다.
- tight frame U-Net: 카이스트에서 최근에 나온 것.
Pose Estimation
자세를 측정하는 것이 목적.
Heat Map
Hour Glass Model(Unet와 비슷한 모델)
관절 부분 1, 나머지는 0인 ground truth값을 가짐
Mask-RCNN
Faster RCNN(Object Detection) + FCN(Semantic Segmentation) = Mask-RCNN(Instance Segmentation)
Mask-RCNN structure
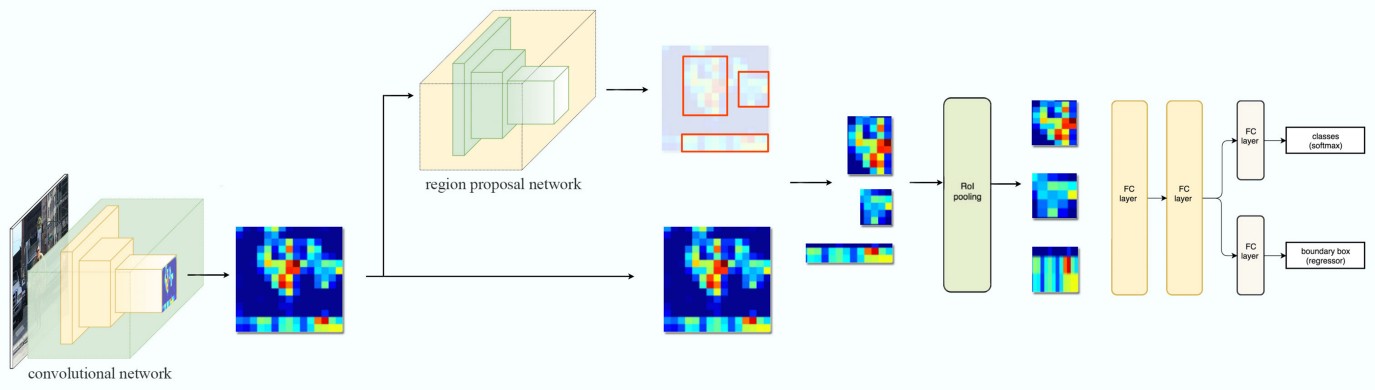
- 출처: https://developpaper.com/mask-r-cnn/
- 계산량은 많지만 세그멘테이션에 대해서는 FCN보다 성능이 좋다!
ROI Align
512 * 512인풋 이미지가 VGG16을 지나 16 * 16으로 작아졌다고 하자.
각 바운딩 박스는 원래 좌표에 비해 어느정도 좌표상의 오차(차이)가 생긴다.(quantization) -> ROI Pooling을 하면 잃어버린 정보가 생김!(소수점을 반올림한 좌표를 가지고 풀링을 해주므로) -> 이를 해결하기 위한 ROI Align
- RoIAlign은 피쳐맵 위에 있는 그리드 포인트로부터 bilinear interpolation을 하여 각 샘플링 포인트의 값을 계산함
Mask R-CNN Customize해서 나만의 디텍션 모델 만들기
https://hansonminlearning.tistory.com/m/16
주말과제 해설 세션
