
[Visual Recognition]Visual Recognition: Object Segmentation, YOLO, SSD 기반의 Object Detection
Visual Recognition: Object Detection(1) - YOLO & SSD
YOLO v1 network structure
Imput image($488 * 488 * 3$) -> GoogLeNet modification(20 layers, $14 * 14 * 1024$) -> 컨볼루션 수행($14 * 14 * 1024$) -> 컨볼루션 수행($14 * 14 * 1024$) -> Pooling 수행($7 * 7 * 1024$) -> Pooling 수행($7 * 7 * 1024$) -> Fully Connected($4096 * 1$) -> Fully Connected($1470 * 1$) -> Reshape($7 * 7 * 30$), 연산을 수행하지 않고 픽셀만 재배열함
YOLO 추론방법
위의 Reshape에서 나온 $7 * 7 * 30$ 로그에 대해 Detection Procedure을 수행하여 영상의 어느 위치에 어떻게 오브젝트가 바운더리가 있는지 찾아낸다.
$7 * 7$의 한 픽셀은 원래 영상에서는 $488 * 488$의 픽셀을 7로 나눈 만큼에 해당된다. 이것이 $7 * 7 * 30$이므로 총 30개의 체널에 대해 1차원의 길이 30짜리 벡터가 만들어진다.
이 길이가 30인 벡터가 갖는 정보는 다음과 같다.
- 30개 중 처음 5개의 정보는 세로로 길쭉한 앵커박스에 대한 정보. 5개 칸의 마지막에 앵커박스의 c값(0 or 1)이 담긴다.
- 그 다음 5개의 정보는 가로로 길쭉한 앵커박스에 대한 정보. 5개 칸의 마지막에 앵커박스의 c값(0 or 1)이 담긴다.
위의 정보를 구성하는 5개의 요소는 다음과 같다.
- x: coordinate of bbox center inside cell
- y: coordinate of bbox center inside cell
- w: bbox width
- h: bbox height
- c: bbox confidence ~ P(앵커박스 안에 어떤 오브젝트가 있을 확률)
- 그 다음 20개의 값은 오브젝트가 해당하는 class의 확률을 학습하는데 쓰인다. class score가 predict됨.
이후 첫번째 앵커박스에 대한 confidence score와 20개의 값을 각각 곱한다. 두번째 앵커박스에 대해서도 마찬가지로 confidence score와 20개의 값을 각각 곱한다. 이 곱은 길이 20의 벡터가 된다.
따라서 $7 * 7$이미지에 대해 각각의 셀마다 2개의 20개짜리 벡터가 나온다. 벡터는 20개의 클래스 요소를 갖는다.(dog/cat/등등…), 모든 셀에 대해 해당 벡터의 같은 위치를 보고 비교한다. 한 class당 총 98개의 score를 비교하개 된다. $7 * 7 * 2 = 98$(49개의 셀에 대해 길이 20의 벡터가 2개씩 있으므로)
예를 들어 dog 클래스일 확률에 대한 앵커박스 벡터의 20개 칸 중 첫번째 칸을 보고, threshold보다 작으면 dog score을 0으로 만든다.
이후 98개의 스코어값을 크기 내림차순으로 소팅한다.
이후 NMS 알고리즘을 사용해 각각의 앵커박스들이 서로 겹치는 정도가 크면(IoU값이 크면) 0으로 만든다. 이 작업을 $7 * 7 * 2 = 98$(49개의 셀에 대해 길이 20의 벡터가 2개씩 있으므로)개의 dog scores에 대해 반복한다.
그러면 대부분의 값이 0이 되고 가장 큰 값이 일부 남는다. 98개 중 큰 값이 남아있는 자리에 해당하는 길이 20의 벡터가 그 큰 값이 해당하던 클래스의 오브젝트가 되므로 이에 따라 박스를 그린다.
YOLO학습
이 부분이 FAST RCNN과 다른 부분이다!
YOLO에서는 Ground truth box가 있고, Ground truth box의 중심점을 포함하고 있는 셀이 있다. Ground truth box의 중심점을 포함하고 있는 셀은 Positive, 그외의 모든 셀은 Negative가 됨.
Positive인 셀은 2개의 앵커박스를 가짐.(가로로 긴 것 하나와 세로로 긴 것 하나) Positive인 셀에 대해서만 Anchor Box들과 Ground Truth box를 비교함. 둘 중 IoU가 큰 것이 무엇인지 계산함. IoU가 큰 anchor box만 confidence(오브젝트일 확률)을 1로 줌. 나머지 anchor box는 confidence(오브젝트일 확률)을 0으로 줌.
- i번째 셀의 j번째 Anchor Box가 object일 때만 1이라는 값을 갖는 함수. 그때 Anchor Box에 대해서만 boundary box에 대한 regression을 수행
- 오브젝트인 앵커박스에 대해서는 confidence 값이 1이 나오도록 학습시킴
- 오브젝트가 아닌 앵커박스에 대해서는 confidence 값이 0이 나오도록 학습시킴
앵커박스가 바운더리를 찾는게 아니고 디텍트를 잘 하도록 하는 용도로 쓰인다. 나머지 x, y, w, h는 알아서 학습되도록 한다.
앵커박스를 사용하지 않으면 해당 위치에 오브젝트가 있는지 없는지를 Ground truth box의 중심점 영역(Positive 영역)만 가지고 판단해야 하는데 이것은 리스크가 크다.(강아지의 일부만 보고 강아지라고 판단.) 앵커박스를 통해 Positive 영역 주변의 것도 보면서 학습해야 리스크를 줄일 수 있다.
yolo v1에서는 앵커박스가 갖는 의미가 그리드 셀이(positive 셀) 오브젝트에 해당하는 그리드 셀인지를 판단하는데 도움을 주는 용도로만 쓰였다. 하지만 positive셀 하나만 가지고는 오브젝트 영역인지 판단하기 어려우므로 더 넓은 영역인 앵커박스를 보며 오브젝트를 판단한다. 앵커박스가 바운더리 박스의 초기치가 되어 초기치에서 시작해 실제 바운딩 박스를 regression으로 찾으라는 것은 v1에서는 갖고 있지 않았다. 그저 detect하는 의미만 있었을 뿐! v2에서는 fast rcnn과 같이 앵커박스가 바운더리 박스의 초기치가 되어 실제 바운더리 박스를 찾아나가게 된다.
YOLO 버전별 비교
- YOLO v1
- Pre-trained Network로 Inception 모델 사용
- Anchor Box 2개(세로로 긴 것/가로로 긴 것)
- Feature Map 크기 $7 * 7$
- 크기가 정해진 Anchor Box가 Object Detect에만 사용
- YOLO v2
- 속도가 빨라짐
- Pre-trained Network로 Darknet-19 모델 사용
- Anchor Box 5개
- Feature Map 크기 $13 * 13$
- K-means로 Anchor Box 크기 결정(데이터셋의 ground truth의 바운더리 박스로부터)
- 데이터셋에서 Ground-truth Bounding Box 추출
- IoU기반의 K-means 알고리즘 - 비슷한 크기의 박스들끼리 그룹으로 묶임 -> 각 그룹별로 중간에 해당하는 박스를 대표 박스로 함 -> 그 박스가 욜로 버전2에서 사용하는 앵커박스가 됨
- YOLO v3
- 속도는 v2보다 좀 느린데, 정확도가 높아짐
- Pre-trained Network로 Darknet-53 모델 사용
- Anchor Box 9개(3개의 대중소 스케일에 대해 3개씩)
- Feature Map 크기 $13 * 13, 26 * 26, 52 * 52$
- K-means로 Anchor Box 크기 결정 + Feature Pyramid 사용
Feature Pyramid
같은 사이즈의 box라도 feature map의 scale에 의해 오브젝트의 detect 여부가 달라진다.
feature map의 스케일이 크면 잘 찾지만 속도가 느리고, 스케일이 작으면 속도는 빠르지만 오브젝트 디텍트가 잘 안될 수있다.
YOLO v3 구조
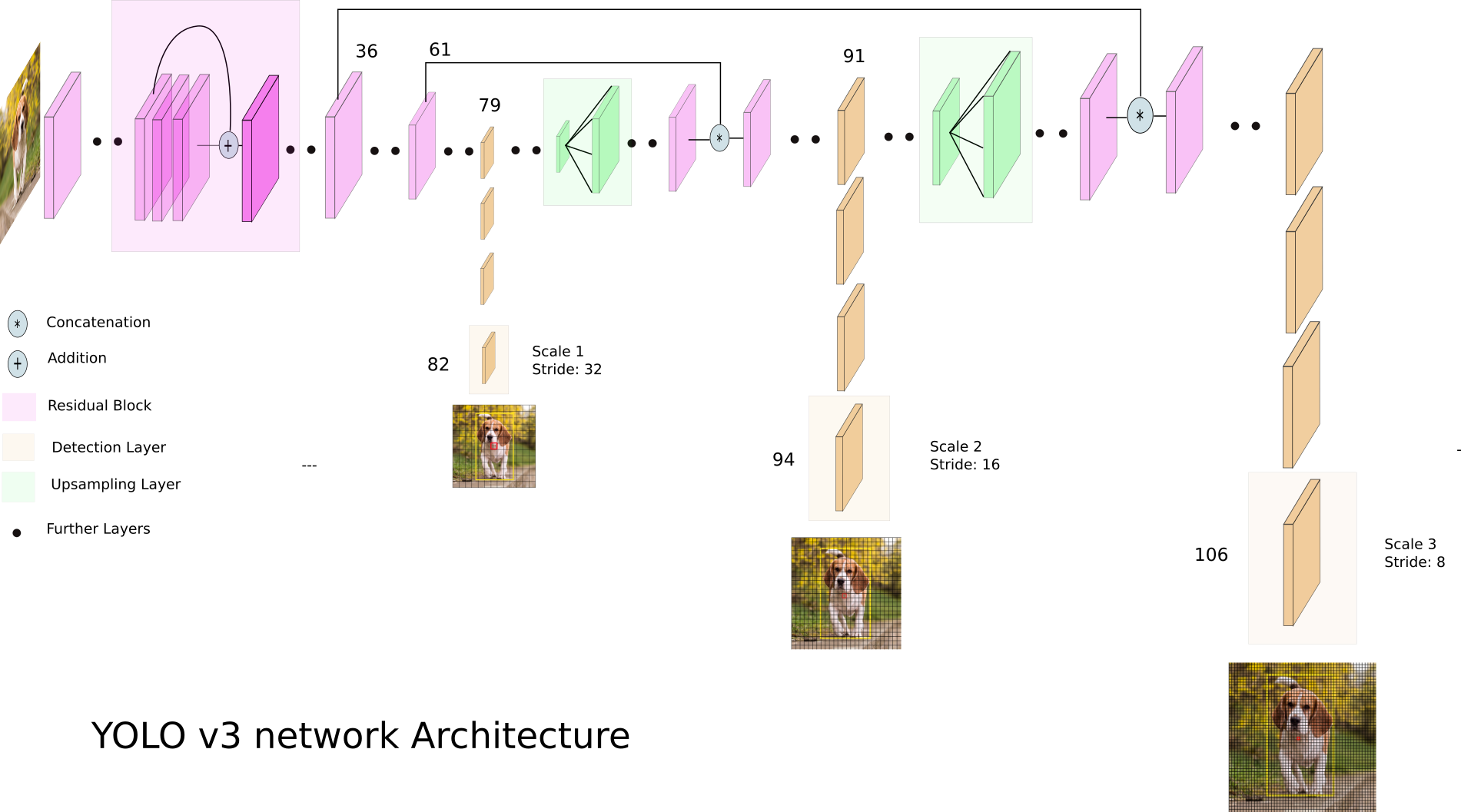
YOLO v1 Feature Map
Anchor box1(5개 값) + Anchor box2(5개 값) + 20개 class = 총 합이 길이가 30인 벡터
YOLO v2 Feature Map
Anchor box1 + Anchor box2 + Anchor box3 + Anchor box4 + Anchor box5
각 Anchor box: x + y + w + h + object score + class score
총 Anchor box 크기: $13 * 13 * 5$($13 * 13$의 앵커박스가 총 5개 있으므로)
YOLO v3 Feature Map
scale1($13 * 13$) - Anchor box1 + Anchor box2 + Anchor box3
scale2($26 * 26$) - Anchor box1 + Anchor box2 + Anchor box3
scale3($52 * 52$) - Anchor box1 + Anchor box2 + Anchor box3
각 Anchor box: t_x + t_y + t_w + t_h + object score + class score
- t_x, t_y, t_w, t_h: 앵커박스의 x, y좌표를 주는게 아니라, 앵커박스의 중심점에서 얼마나 움직여야 하는지에 대한 값
총 Anchor box 크기: $13 * 13 * 3 + 26 * 26 * 3 + 52 * 52 * 3$
SSD(Single Shot Detector)
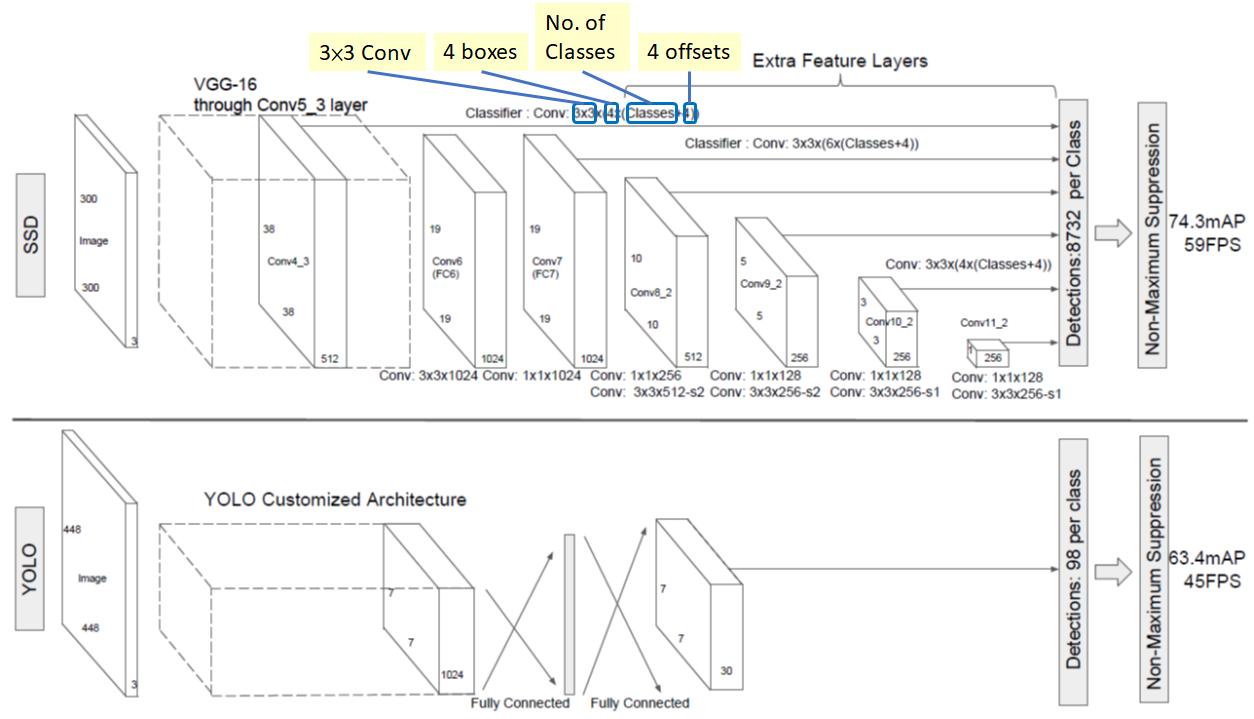
- 컨볼루션을 여러번 거치며 피쳐맵 사이즈가 조금씩 줄어든다. 다양한 크기의 피쳐맵에서 여러개의 앵커박스를 뽑아낸다. 클래스마다 약 8932개의 앵커박스가 나온다. 이후 NMS를 수행하여 앵커박스 많이 겹치는 앵커박스들을 버린다.
- 출처: https://towardsdatascience.com/review-ssd-single-shot-detector-object-detection-851a94607d11
Bounding Box 갯수
예를 들어 Conv4_3은 사이즈가 $38 * 38 * 512$, $3 * 3$ conv를 적용하는데, 4개의 박스가 있고, 각 박스는 class갯수(c) + 4의 출력을 가짐.
그러므로 Conv4_3의 출력의 사이즈는 $38 * 38 * 4 * (c + 4)$임.
오브젝트의 종류가 20이고 background class 1개를 추가하면 출력의 사이즈는 $38 * 38 * 4 = 144,400$이 됨.
바운딩박스의 갯수는 $38 * 38 * 4 = 5776$이 됨.
다른 컨볼루션 레이어들의 경우:
- Conv7: $19 * 19 * 6 = 2166$개의 박스(위치마다 6개의 박스)
- Conv8_2: $10 * 10 * 6 = 600$개의 박스(위치마다 6개의 박스)
- Conv9_2: $5 * 5 * 6 = 150$개의 박스(위치마다 6개의 박스)
- Conv10_2: $3 * 3 * 4 = 36$개의 박스(위치마다 4개의 박스)
- Conv11_2: $1 * 1 * 4 = 4$개의 박스(위치마다 4개의 박스)
그러므로 총 합쳐서 박스의 총갯수는 $5776 + 2166 + 600 + 150 + 36 + 4 = 8732$임.
SSD Inference
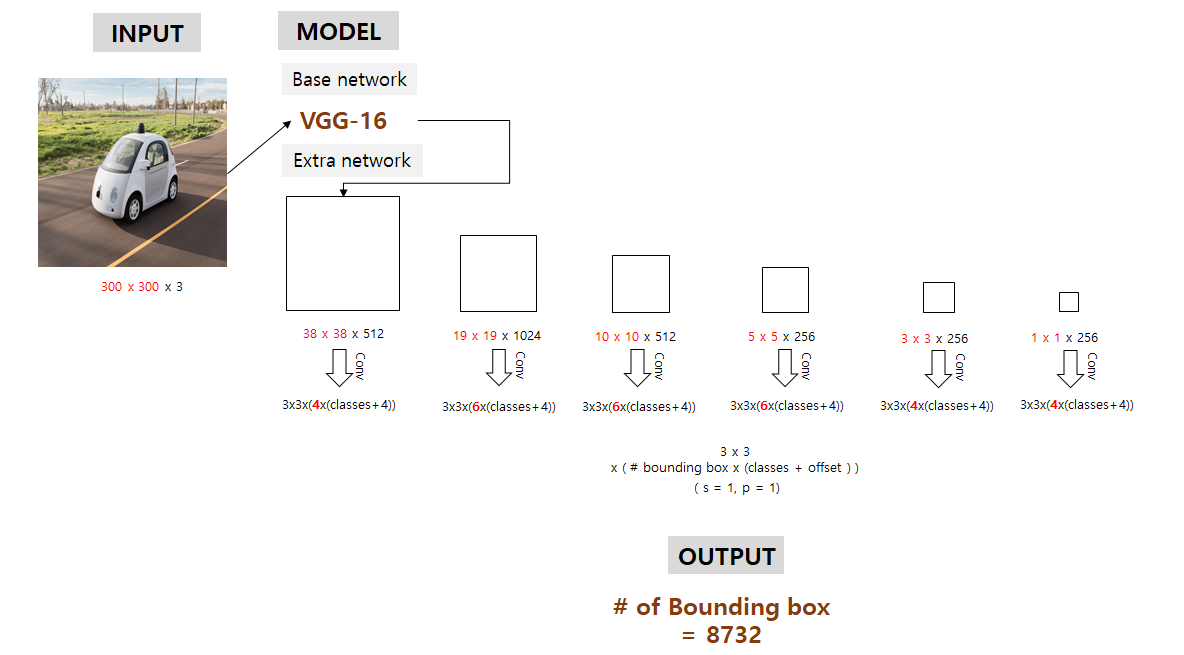
- 출처: https://taeu.github.io/paper/deeplearning-paper-ssd/
- 이미지를 사전 학습된 베이스 네트워크에 넣고, 결과를 보고 컨볼루션을 수행하여 각각의 바운딩 박스를 도출한다.
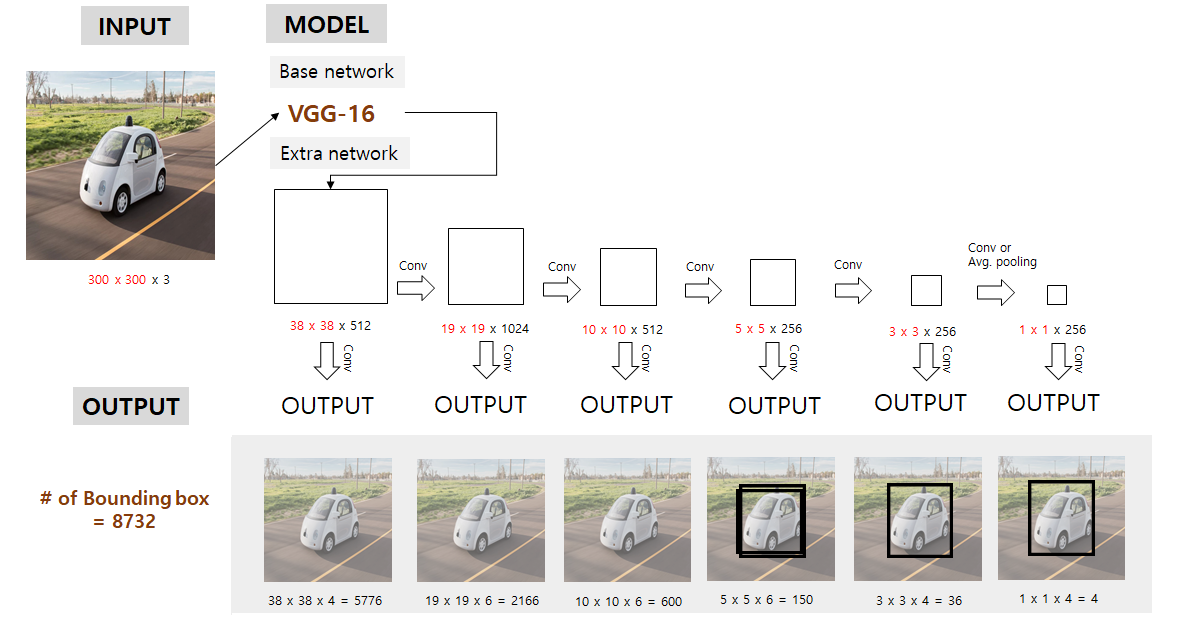
- 출처: https://taeu.github.io/paper/deeplearning-paper-ssd/
- 4번째 정도의 크기에서, 바운딩 박스 안에 영상이 다 들어올만큼 영상이 작아진다.
- 마지막 아웃풋으로 갈수록 영상이 작아지면서 바운딩 박스도 작아진다.
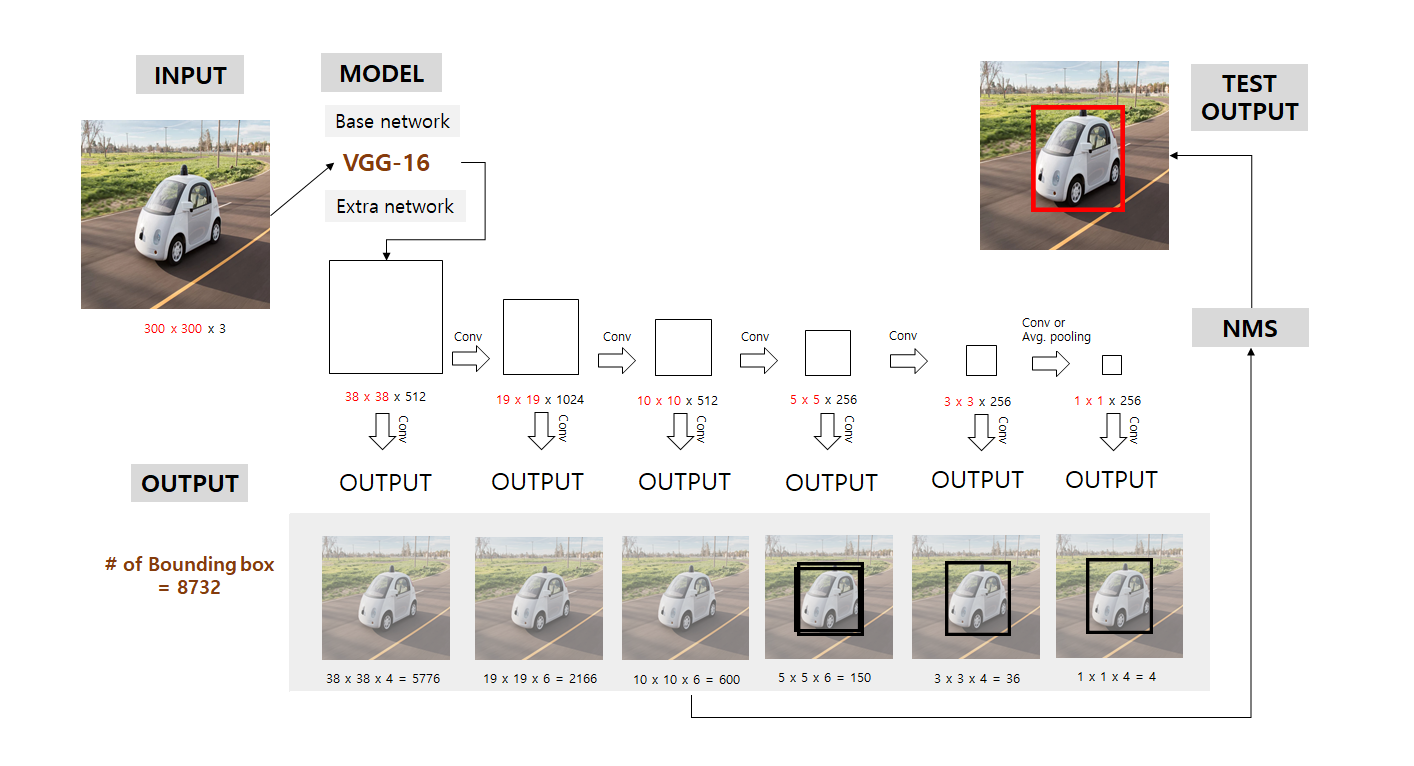
- 출처: https://taeu.github.io/paper/deeplearning-paper-ssd/
- 최종적으로 수많은 바운딩 박스가 있었지만 각 레벨마다 살아남은 바운딩박스는 몇개 되지 않는다. NMS를 수행하여 최종적으로 오브젝트 스코어가 가장 큰 박스가 도출된다.