
[Visual Recognition]Visual Recognition: Object Detection, Faster RCNN
Visual Recognition: Object Detection(1) - Fast RCNN
Object Detection 문제정의
영상안에 있는 모든 물체(object)들과 그것들의 위치(영역)을 함께 찾는다.
- Classification + Localization = Object Detection
- 입력: 영상, 출력: 벡터(9개)
- 입력 영상이 뉴럴 네트워크의 여러 필터를 거치게 된다. 마지막 단에는 우리가 관심있는 클래그의 개수만큼의 Output이 나온다. (예: 보행자 / 차 / 오토바이 / 배경 일 확률에 대한 4가지의 Output)
- 여기에 localization이 추가되어 클래스의 정보와 더불어 위치 정보가 추가되어 도출된다 (예: 물체가 있느냐 / 물체의 중심점의 x좌표 / 물체의 중심점의 y좌표 / 물체의 넓이 / 물체의 높이)
- 결론적으로, 입력 영상 -> 9개의 원소를 갖는 벡터 출력하는 네트워크를 만드는 것이다.
- weight의 업데이트는, 현재의 예측치와 Ground Truth의 차이가 줄어들도록 CNN을 업데이트한다.
- 로스함수: 현재의 예측치 - Ground Truth값의 제곱. 로스함수를 최소화하는 것이 목표.
- 현재의 예측치는 인공신경망의 파라미터에 의존하는 함수임
- Object Detection에서는 box가 반드시 한 개인 것은 아님. 영상 1개에 대하여 벡터 1개만으로는 모든 object가 표현이 안됨. 따라서 여러 오브젝트에 대해 박스체킹이 됨.
- 어느 위치에 오브젝트가 있는지 찾아줘야함. 오브젝트 영역의 크기도 결정해야 함. + 어떤 오브젝트인지도 알려줘야 함(분류) -> 이런 여러 문제를 동시에 풀기가 쉽지 않다.
- 어느 위치에 오브젝트가 있는지 찾아줘야함. 오브젝트 영역의 크기도 결정해야 함. + 어떤 오브젝트인지도 알려줘야 함(분류) -> 이런 여러 문제를 동시에 풀기가 쉽지 않다.
Object Detection 요소기술
- Region Proposal: Object가 있을만한 영역을 다수 추천
- Non-max Suppression: 겹치는 영역을 제거
- Classification: 영역속의 Object를 분류
- Bounding Box Regressior: Object 영역을 미세조정
Faster RCNN 기본 flow
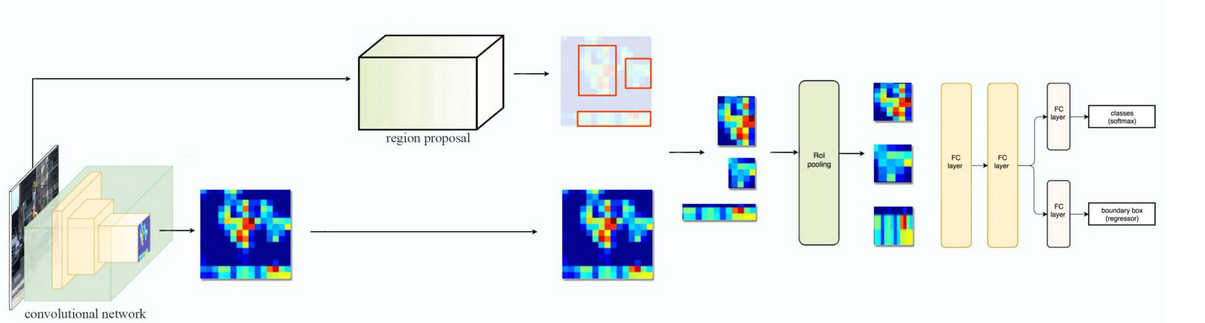
- 출처: https://medium.com/datadriveninvestor/review-on-fast-rcnn-202c9eadd23b
- Pre-trained 모델을 base network라고도 부른다. 처음 나왔을땐 VGGNet을 썼고, Mobilenet, ResNet등을 사용할 수 있다.
- Rol Pooling은 Region Proposal을 통해 나온 서로 다른 크기의 영역들을 같은 사이즈들로 맞춘다. (fully connected layer는 고정된 크기를 input으로 받기 때문에)
- Region proposal에서는 대충의 바운더리가 나왔다면 FC레이어 이후에는 그 오브젝트의 종류별로 클래시피케이션을 수행한다.
Base Network
- 초기의 논문에서는 VGG Net을 썼음.
- 2242243 사이즈의 이미지가 들어오면 컨볼루션+pooling을 수행하여 5번의 pooling layer를 거쳐 77512가 된다. 즉 feature map의 사이즈가 224/2^5 = 224/32 = 7, 7*7크기의 이미지가 된 것. 풀링 레이어의 개수는 쓰기 나름이다.
- 이 결과를 Region proposal의 네트워크에 집어넣게 된다.
Region Proposal Architecture
- Region proposal의 네트워크는 다음과 같이 구성된다.
- 3*3 convolution(아래와 같이 양쪽으로 나눠진다. 따라서 2개의 output이 나온다.): 512개의 output channels
- 1*1 convolution: 2k(=36)개의 output channels
- 1*1 convolution: 4k(=36)개의 output channels
- 각각의 컨볼루션은 각각의 로스를 최소화한다.
- 각각의 컨볼루션은 각각의 로스를 최소화한다.
- 3*3 convolution(아래와 같이 양쪽으로 나눠진다. 따라서 2개의 output이 나온다.): 512개의 output channels
3*3 Convolution 후의 Output
- 224 * 224 사이즈의 이미지 -> 3 * 3 컨볼루션을 통과하여 7 * 7 사이즈의 이미지
- 7 * 7 feature map에서의 한 픽셀은 원래영상(224*224)에서 32 * 32에 해당하는 영역임.
1*1 convolution
- 1 * 1 컨볼루션은 3차원 필터인데 각 픽셀의 width, height가 1이다.
- 3 * 3 컨볼루션을 통해 나오는 feature에 1 * 1 컨볼루션을 씌우면 겹치는 각 픽셀 영역에서의 필터값과 1 * 1 컨볼루션의 피쳐맵의 값이 곱해진다. 겹치는 각 픽셀마다 하나의 값이 나온다.
- 결과적으로 하나의 맵이 나온다.
1*1 Convolution 후의 Output
- 1*1 Convolution을 통과하면 하나의 맵이 나온다.
- 2개의 1*1 Convolution은 각각 2k의 output channel(1k의 맵 2개)
- 여기에서 각 맵의 위치 2개를 통해 Objectness 벡터가 나온다
- 이 값은 해당 픽셀 위치에 오브젝트가 있을 확률을 알려준다.
- 그리고 4k의 output channel(1k의 맵 4개)이 도출된다.
- 여기에서 각 맵의 위치 4개를 통해 Bounding Box 벡터가 나온다
- 이 값의 2개는 오브젝트를 감싸는 바운딩 박스의 중심점을 알려준다.
- 이 값의 나머지 2개는 중심점을 기준으로 하여 박스의 width, height를 알려준다.
- Objectness 벡터와 Bounding Box 벡터를 합쳐 같은 위치에 해당하는 feature vector가 된다.(오브젝트가 있을 확률 + 오브젝트 박스의 중심점 + 너비와 높이의 정보를 갖고있다.)
IoU(Intersection over Union) measure(측정도구)
IoU = 예측값과 참값의 교집합 / 예측값과 참값의 합집합
IoU = 0.1 # Poor
IoU = 0.6 # Good
IoU = 0.8 # Excellent
IoU가 1이면 가장 최댓값, 예측값과 참값이 모두 일치할 때.
IoU가 0이면 가장 최솟값, 예측값과 참값이 아예 일치하지 않을 때.
0과 1사이의 값을 갖고, 1에 가까울수록 좋은 성능을 가진 것이다.
Objectness 벡터
- 2개의 벡터: 이 영역이 오브젝트에 해당하는 영역인지 아닌지(오브젝트일 확률/오브젝트 아닐 확률)
- 4개의 벡터: 이 영역이 오브젝트에 해당하는 영역이라면 오브젝트의 바운딩 박스의 위치와 크기는 어떻게 되는지(오브젝트의 중심점의 x, y좌표, 오브젝트의 바운더리의 너비, 높이)
Objectness의 기준
- 2개의 벡터: 이 영역이 오브젝트에 해당하는 영역인지 아닌지(오브젝트일 확률/오브젝트 아닐 확률) 이 2개의 값의 기준을 알아보자.
- 훈련시 이 영역이 오브젝트 영역인지 아닌지 판단하는 방법:
- Ground Truth object 영역(사람이 손수 매뉴얼하게 오브젝트를 구분해둔 것의 데이터셋, 참값)과의 IoU를 계산하여 IoU가 threshold보다 크면 이 영역을 오브젝트 영역이라고 판단. 작으면 오브젝트 영역이 아니라고 판단.
- 어떤 오브젝트 영역의 일부 -> IoU가 작기 때문에 오브젝트가 아니라고 판단됨! 사실 오브젝트 전체 영역보다 작을 뿐 오브젝트 영역의 일부인데 잘못 판단된 것임.
- IoU로 판단하지 말고 Ground Truth object 영역과의 교집합으로 판단하면 되지 않을까?
- 그러면 오브젝트 영역의 일부가 오브젝트 영역으로 판단이 되기는함.
- 문제는 Box Boundary Regressor(Object 영역을 미세조정함)가 할 일이 어려워진다.
Boundary Box Regressor
- Box Boundary Regressor(네트워크):
- 오브젝트의 바운더리 박스의 좌표를 찾는 일을 함
- 현재 ‘임시’로 지정한 바운더리 박스가 오브젝트의 실제 바운더리 박스와 많이 다르면 일이 어려워진다. = 이런 매핑을 잘 해주는 (33, 11 컨볼루션 레이어)를 학습시키기가 어려워진다 = 학습시킨 (33, 11 컨볼루션 레이어)의 성능이 떨어진다.
- 4k의 output channel(1k의 맵 4개)의 아웃풋에서 일어나며, 중심점으로부터 가로-세로로 얼마나 벗어났는지 계산한다.
- height, width, y_center, x_center이 도출된다.
- 문제점: 만약 오브젝트의 일부 영역은 오브젝트의 영역에 해당하는 것으로 학습했다고 했을 때 이것을 잘 학습했다고 할 수 있는지?
- 오브젝트의 일부 영역만 보고 이렇게 생겼다면 오브젝트 영역이다 라고 배워도 되는걸까?
- 오브젝트의 전체 영역을 보고 이렇게 생겼다면 오브젝트 영역이라고 해야 더 잘 배운 것으로 볼 수 있다. 나중에 이와 비슷하게 생긴 것을 오브젝트라고 판단하기 때문에.
Anchor Box
- Anchor Box: 정해진 크기와 비율을 가진 미리 정의된 후보 box(9개)
- 11, 22, 24, 84등 여러개의 사이즈를 가진 후보들을 만든다. 어떤 사이즈가 더 좋은지는 계속 연구중!
- IoU < 0.6: 이 위치에서의 픽셀 영역은 ‘non- object’ Anchor box
- IoU > 0.6: 이 위치에서의 픽셀 영역은 ‘object’ Anchor box
- 2개의 벡터: 이 영역이 오브젝트에 해당하는 영역인지 아닌지(오브젝트일 확률/오브젝트 아닐 확률)
- BAB: Background Anchor Box
- OAB: Object Anchor Box
- BAB, OAB인 9개의 정해진 크기와 비율을 가진 미리 정의된 후보 anchor box들이 한줄로 합쳐진다. 이것을 정답박스라고 한다.
- 길이 2*k=9, k는 Anchor box의 갯수
- 각 위치마다 정답이 나오고, 크기는 7*7이 된다.
- 정답이 이와 같이 나오도록 학습을 해야 한다.