
[데이터 씹고 뜯고 맛보고 즐기기]8,9강:EDA
4. Exploratory Data Analysis
탐색적 데이터 분석을 통해 데이터를 통달해봅시다. with Titanic Data
- 라이브러리 준비
- 분석의 목적과 변수 확인
- 데이터 전체적으로 살펴보기
- 데이터의 개별 속성 파악하기
탐색적 데이터 분석 - EDA
EDA?
데이터를 분석하는 기술적 접근은 매우 많다. CNN, RNN, …다양한 인공지능 기술들이 쏟아져나온다. 하지만 데이터가 가지는 본질적인 의미를 망각해서는 안된다. EDA는 데이터 그 자체에 적성과 특성을 요목조목 육안으로 확인하는 과정, 데이터 그 자체만으로부터 인사이트(시각화, 통계적 수치, numpy/pandas의 여러 컨테이너들)를 얻어내는 접근법이다!
EDA의 Process
- 분석의 목적(명확하게!)과 변수 확인(즉, column을 확인하는 것)
- 데이터 전체적으로 살펴보기 (상관관계 분석, 결측치 즉 NA가 없는지)
- 데이터의 개별 속성 파악하기(feature 등)
EDA with Example - Titanic
https://www.kaggle.com/c/titanic
머신러닝의 굉장히 유명한 데이터셋인 타이타닉 데이터셋이다. 데이터에서 얻을 수 있는 정보가 굉장히 많고, 적용해볼 수 있는 머신러닝 테크닉이 정말 많은 훌륭한 데이터셋이다. (컴퓨티 비전에서 자주 쓰이는 레나씨의 사진이 떠오른다..)
0. 라이브러리 준비
## 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline # matplotlib 라이브러리를 인라인 환경에서 사용함을 반드시 명시
## 동일 경로에 "train.csv"가 있다면:
## 데이터 불러오기
titanic_df = pd.read_csv("./titanic/train.csv")
1. 분석의 목적과 변수 확인
- 살아남은 사람들은 어떤 특징을 가지고 있었을까?
- Kaggle 사이트의 타이타닉 데이터셋에서 Data > Data Dictionary, Variable Notes를 확인한다.
## 상위 5개 데이터 확인하기
titanic_df.head(5)
# NaN은 결측치이다. 결측치는 중요한 단서이다. 이것을 메꿔야할 수도 있고, 이 결측치가 의미있는 것일수도 있다.
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
## 각 Column의 데이터 타입 확인하기
titanic_df.dtypes
# object는 이름이나 성별이다.
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
2. 데이터 전체적으로 살펴보기
## 데이터 전체 정보를 얻는함수 : .describe()
titanic_df.describe() # 수치형 데이터에 대한 요약만을 제공
# 따라서 아까에 비해 column이 줄어들었다!
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
## 상관계수 확인!
titanic_df.corr() # 상관계수 행렬 출력
# Pclass와 Survived의 상관계수도 눈여겨볼 만 하다.
# Pclass와 Fare의 경우 비쌀수록 높은 클래스의 좌석을 이용했을 것이므로 음의 큰 상관관계가 나온다.
# Correlation is NOT Causation
# 상관성 : A up, B up, ... (A가 증가하면 B도 증가하는 경향성 등을 나타내는 수치)
# 인과성 : A -> B (A로부터 B가 발생한다는 종속관계를 의미)
# 이 두가지를 꼭 구분해서 사용해야 한다.
# 상관계수가 유의미하게 나왔다고 해서 이 둘 사이에 인과성이 꼭 존재하는 것은 아니다.
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| PassengerId | 1.000000 | -0.005007 | -0.035144 | 0.036847 | -0.057527 | -0.001652 | 0.012658 |
| Survived | -0.005007 | 1.000000 | -0.338481 | -0.077221 | -0.035322 | 0.081629 | 0.257307 |
| Pclass | -0.035144 | -0.338481 | 1.000000 | -0.369226 | 0.083081 | 0.018443 | -0.549500 |
| Age | 0.036847 | -0.077221 | -0.369226 | 1.000000 | -0.308247 | -0.189119 | 0.096067 |
| SibSp | -0.057527 | -0.035322 | 0.083081 | -0.308247 | 1.000000 | 0.414838 | 0.159651 |
| Parch | -0.001652 | 0.081629 | 0.018443 | -0.189119 | 0.414838 | 1.000000 | 0.216225 |
| Fare | 0.012658 | 0.257307 | -0.549500 | 0.096067 | 0.159651 | 0.216225 | 1.000000 |
## 결측치 확인
titanic_df.isnull().sum()
# Age, Cabin, Embarked에 결측치 발견!
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
3. 데이터의 개별 속성 파악하기
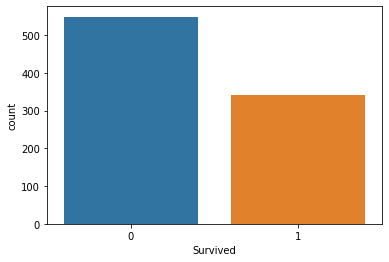
1. Survived Column
## 생존자, 사망자 명수는?
titanic_df['Survived'].sum() # 생존자 명수
342
titanic_df['Survived'].value_counts() # 사망자, 생존자 명수
0 549
1 342
Name: Survived, dtype: int64
## 생존자수와 사망자수를 Barplot으로 그려보기
## sns.countplot()사용. seaborn이 깔끔하다~
sns.countplot(x='Survived', data=titanic_df) # 0은 사망자, 1은 생존자
plt.show()
2. Pclass
# Pclass에 따른 인원 파악
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).count()
| Survived | |
|---|---|
| Pclass | |
| 1 | 216 |
| 2 | 184 |
| 3 | 491 |
# Pclass에 따른 생존자 인원은 어떻게 알 수 있을까?
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).sum()
# survived가 1인 개수를 이렇게 셀 수 있다!
| Survived | |
|---|---|
| Pclass | |
| 1 | 136 |
| 2 | 87 |
| 3 | 119 |
# 생존 비율?
# sum/count이다.
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).mean()
# Pclass가 높을수록 생존률이 높은 상관관계가 있음을 알 수 있다.
| Survived | |
|---|---|
| Pclass | |
| 1 | 0.629630 |
| 2 | 0.472826 |
| 3 | 0.242363 |
# 히트맵 활용
sns.heatmap(titanic_df[['Pclass','Survived']].groupby(['Pclass']).mean())
plt.plot()
[]

Sex
titanic_df[['Sex', 'Survived']]
| Sex | Survived | |
|---|---|---|
| 0 | male | 0 |
| 1 | female | 1 |
| 2 | female | 1 |
| 3 | female | 1 |
| 4 | male | 0 |
| ... | ... | ... |
| 886 | male | 0 |
| 887 | female | 1 |
| 888 | female | 0 |
| 889 | male | 1 |
| 890 | male | 0 |
891 rows × 2 columns
# groupby의 기준을 두개를 적용시키기.
titanic_df.groupby(['Survived', 'Sex'])['Survived'].count()
Survived Sex
0 female 81
male 468
1 female 233
male 109
Name: Survived, dtype: int64
# sns.catplot
# col : survived에 대한 케이스 분류
# x : 가로축 plot에 대한 기준
# kind : countplot을 이용함
sns.catplot(x='Sex', col='Survived', kind='count', data=titanic_df)
plt.show()
# 인사이트 : 남성이 더 많이 죽음, 여성이 더 많이 살아남음
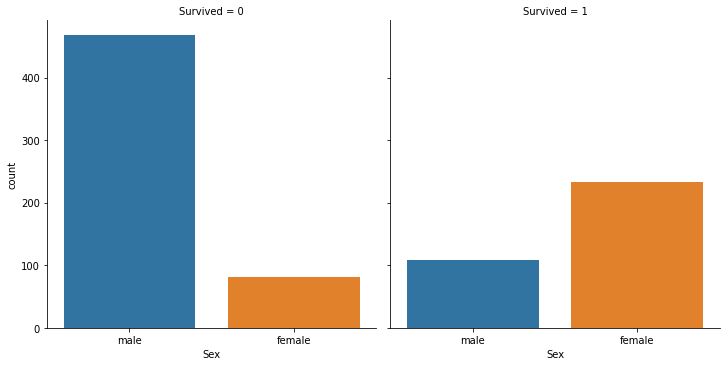
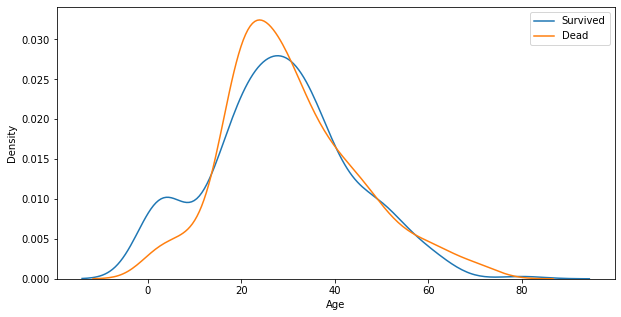
4. Age
Remind : 결측치 존재!
titanic_df.describe()['Age']
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
## Survived 1, 0과 Age의 경향성
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
# 1, 1는 가로엔 몇개, 세로엔 몇개의 그래프를 그릴 것인지.
# 한 axis 위에 두개의 그래프를 그릴 것이다.
sns.kdeplot(x=titanic_df[titanic_df.Survived == 1]['Age'], ax=ax)
sns.kdeplot(x=titanic_df[titanic_df.Survived == 0]['Age'], ax=ax)
plt.legend(['Survived', 'Dead']) # 범위
plt.show()
# 인사이트 : 어린아이들 경우 생존 비율이 높음. 20~30대 청년들은 사망 비율이 높음. 고령층의 경우 사망 비율이 높다.
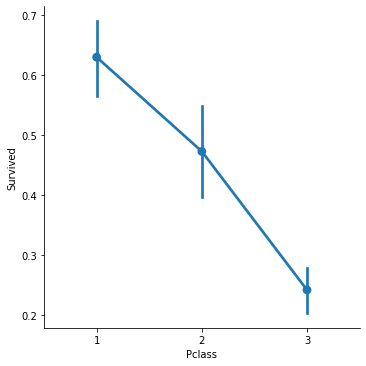
Appendix 1. Sex + Pclass vs Survived
sns.catplot(x='Pclass', y='Survived', kind='point', data=titanic_df)
plt.show()
# 포인트 그래프의 경우 점이 추정치를 의미한다.
# 막대기는 신뢰구간이다.
# Pclass가 1일수록 생존률이 높음을 알 수 있다.
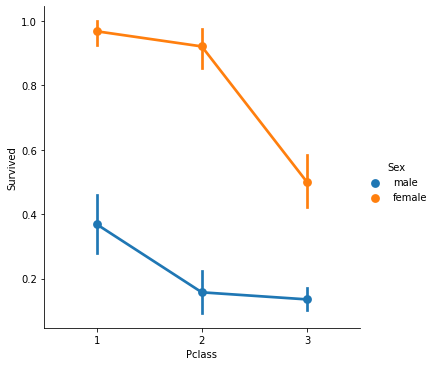
sns.catplot(x='Pclass', y='Survived', hue='Sex', kind='point', data=titanic_df)
plt.show()
# hue를 성별로 줌으로써 두가지 그래프를 그릴 수 있다.
# 여성이면서 1등석이면 생존률이 거의 1, 매우 높다. 반면 남성은 낮다.
# 여러 컬럼에 따라 이렇게 분석해보는 것도 중요하다.
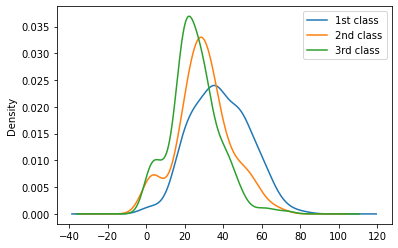
Appendix 2. Age + Pclass
## Age graph with Pclass
titanic_df['Age'][titanic_df.Pclass == 1].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 2].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 3].plot(kind='kde')
plt.legend(['1st class', '2nd class', '3rd class']) # 범주
# Pclass별로 Age 그래프를 그릴 수 있다.
# 인사이트 : 높은 클래스일수록 나이대가 더 높아진다.
<matplotlib.legend.Legend at 0x12b5c6160>
결측치 처리하는 방법
- 제거한다.
- -> 집단의 크기가 달라질 수 있는 문제 발생
- 대체한다.
- 더미 대체(의미 없는 값으로 대체, 0)
- 평균 대체(평균값으로 대체), mean
- 빈도 대체(최빈값으로 대체)
- 회귀 대체(회귀식을 구한 후 예측값으로 대체)
- -> 대치에 따른 오차가 필연적으로 발생
이상치 처리하는 방법
- 제거한다.
- 입력 Error/Outlier가 굉장히 적은 경우
- 절사평균
- 대치한다
- 범주별 mean/median/mode
- Bining
- 스케일링 or 정규화 -> 이상치와 다른 값들의 간극 좁히기